Documentation Index
Fetch the complete documentation index at: https://docs.flowx.ai/llms.txt
Use this file to discover all available pages before exploring further.
Did you know?
Overview
Integration Designer facilitates the integration of the FlowX platform with external systems, applications, and data sources.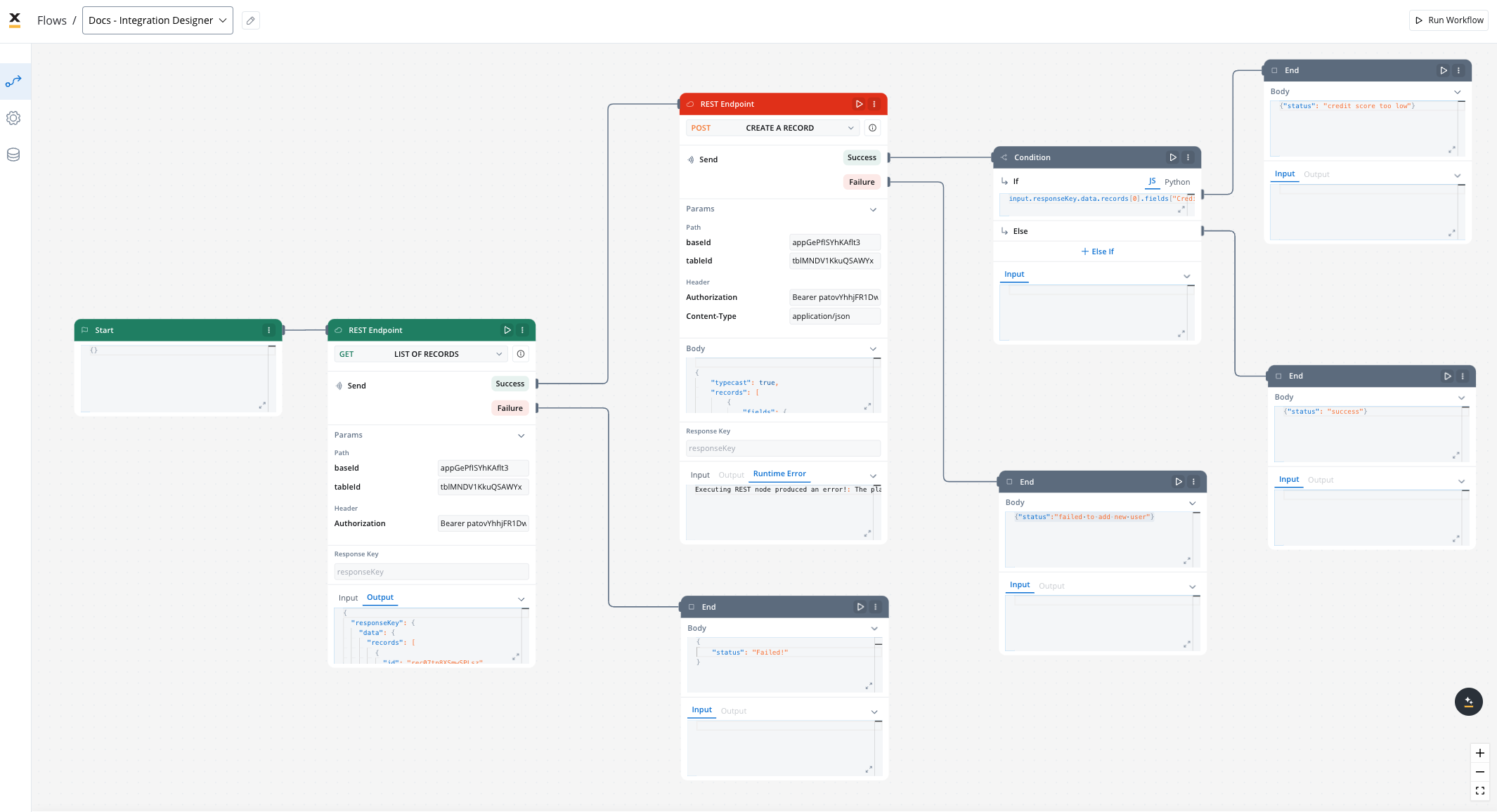
Key features
Drag-and-Drop Simplicity
Visual REST API Integration
Managing integration endpoints
Data Sources
A data source is a collection of resources—endpoints, authentication, and variables—used to define and run integration workflows.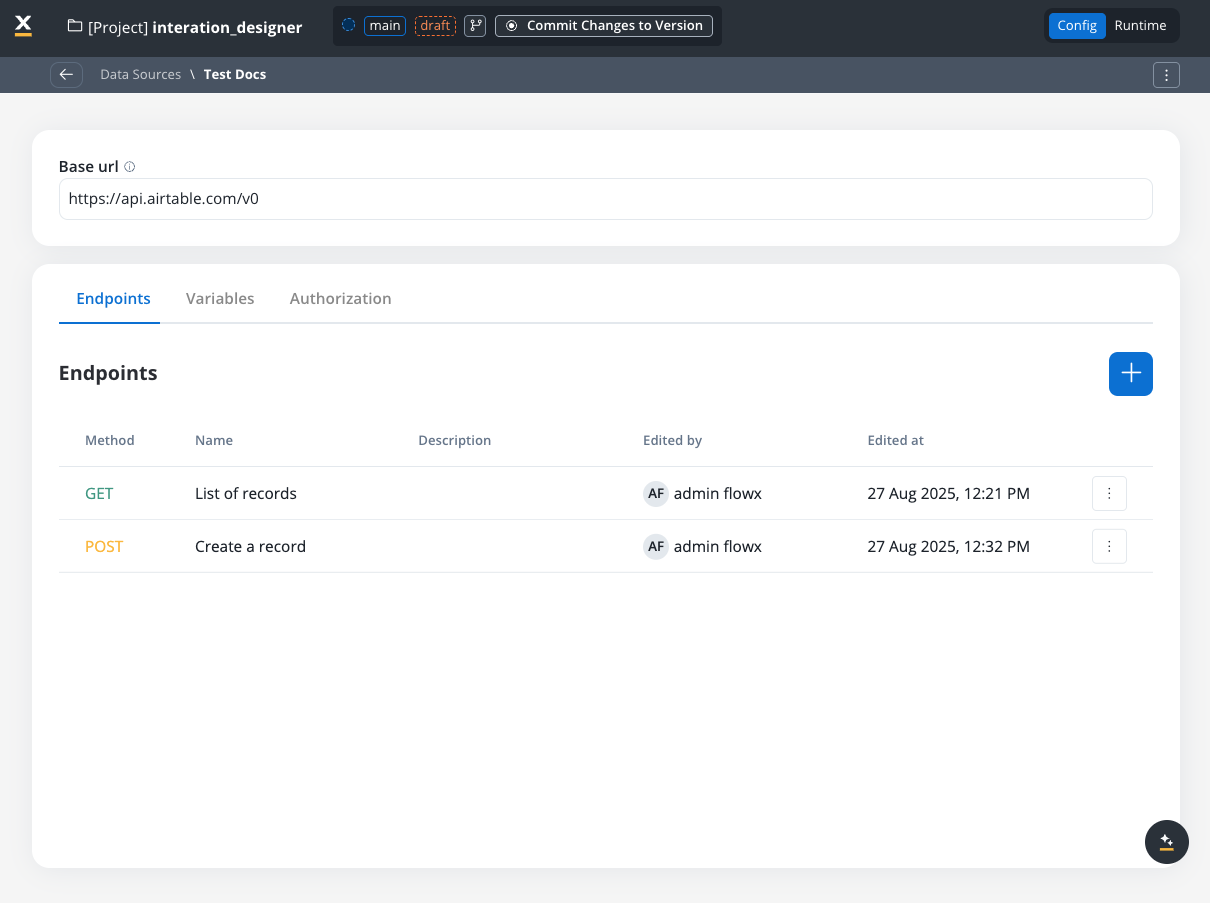
Creating a new data source definition
With Data Sources feature you can create, update, and organize endpoints used in API integrations. These endpoints are integral to building workflows within the Integration Designer, offering flexibility and ease of use for managing connections between systems. Endpoints can be configured, tested, and reused across multiple workflows, streamlining the integration process. Go to the Data Sources section in FlowX Designer at Workspaces -> Your workspace -> Projects -> Your project -> Integrations -> Data Sources.- Creation modal: clicking New Data Source opens a modal where each connector type appears as its own tile with an icon. Use the search box to filter tiles by name. Pick a tile, give the data source a name, and click Create to open the configuration page.
- List view: each entry shows the connector’s icon and type. Use the type filter at the top to scope the list to a specific connector (REST, FlowX Database, Email, MCP Server, Knowledge Base, etc.).
- Unified settings layout: every data source type now uses the same card-based settings layout, so the configuration experience is consistent across connectors.
- Save with incomplete configuration: you can create and save a data source even when some fields (credentials, endpoints) are not yet available. The data source can be referenced in workflows and processes immediately, but it will only operate at runtime once required fields are filled in.
Data sources types
There are multiple types of data sources available: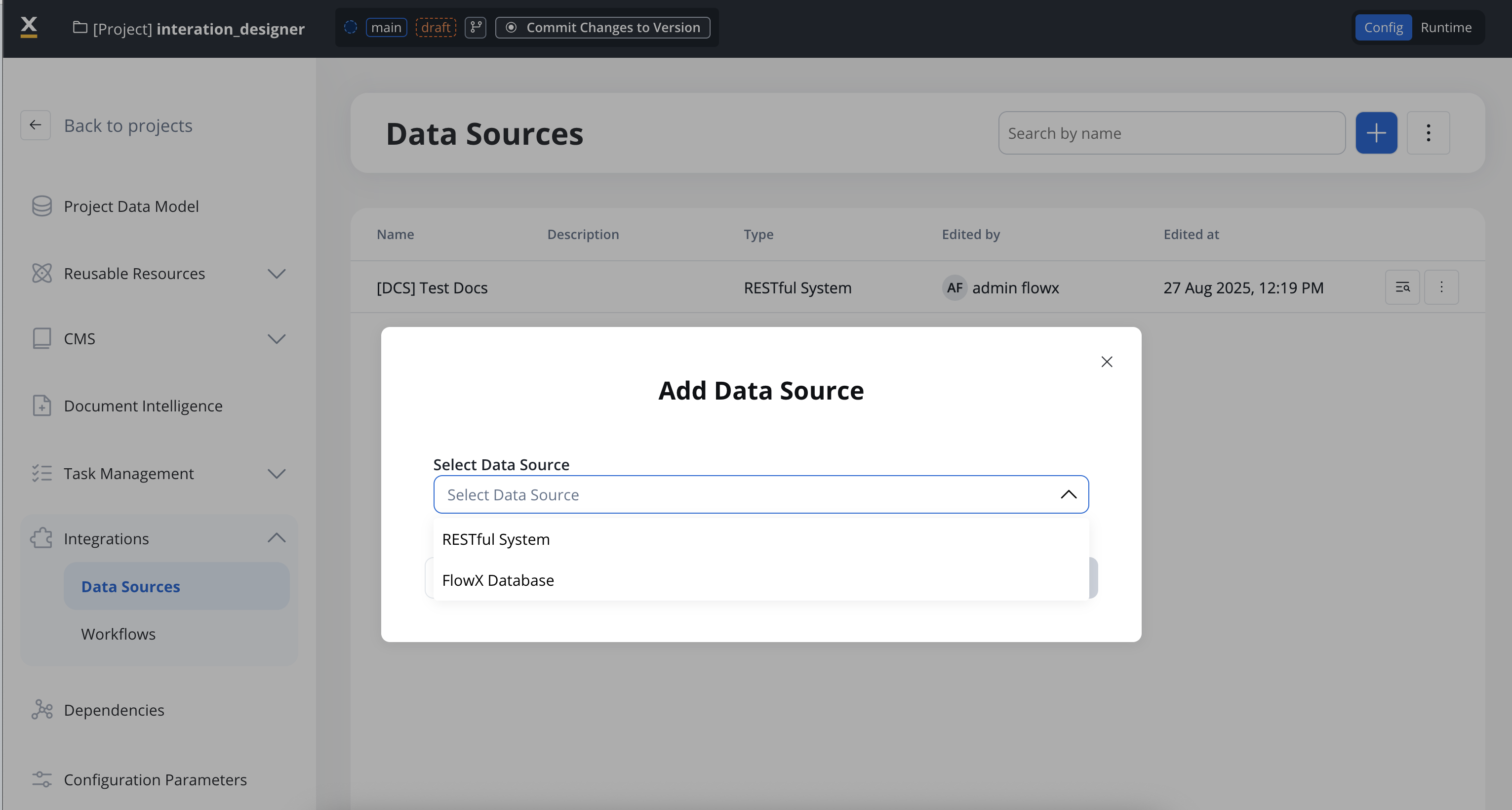
RESTful System
FlowX Database
Unmanaged MongoDB
MCP Integration
FlowX Knowledge Base
Email Trigger
Email Sender
Incoming Webhook
RESTful System
Add a New Data Source, set the data source’s unique code, name, and description:- Select Data Source: RESTful System
- Name: The data source’s name.
- Code: A unique identifier for the external data source.
- Base URL: The base URL is the main address of a website or web application, typically consisting of the protocol (
httporhttps), domain name, and a path. - Description: A description of the data source and its purpose.
- Enable enumeration value mapping: If checked, this system will be listed under the mapped enumerations. See enumerations section for more details.
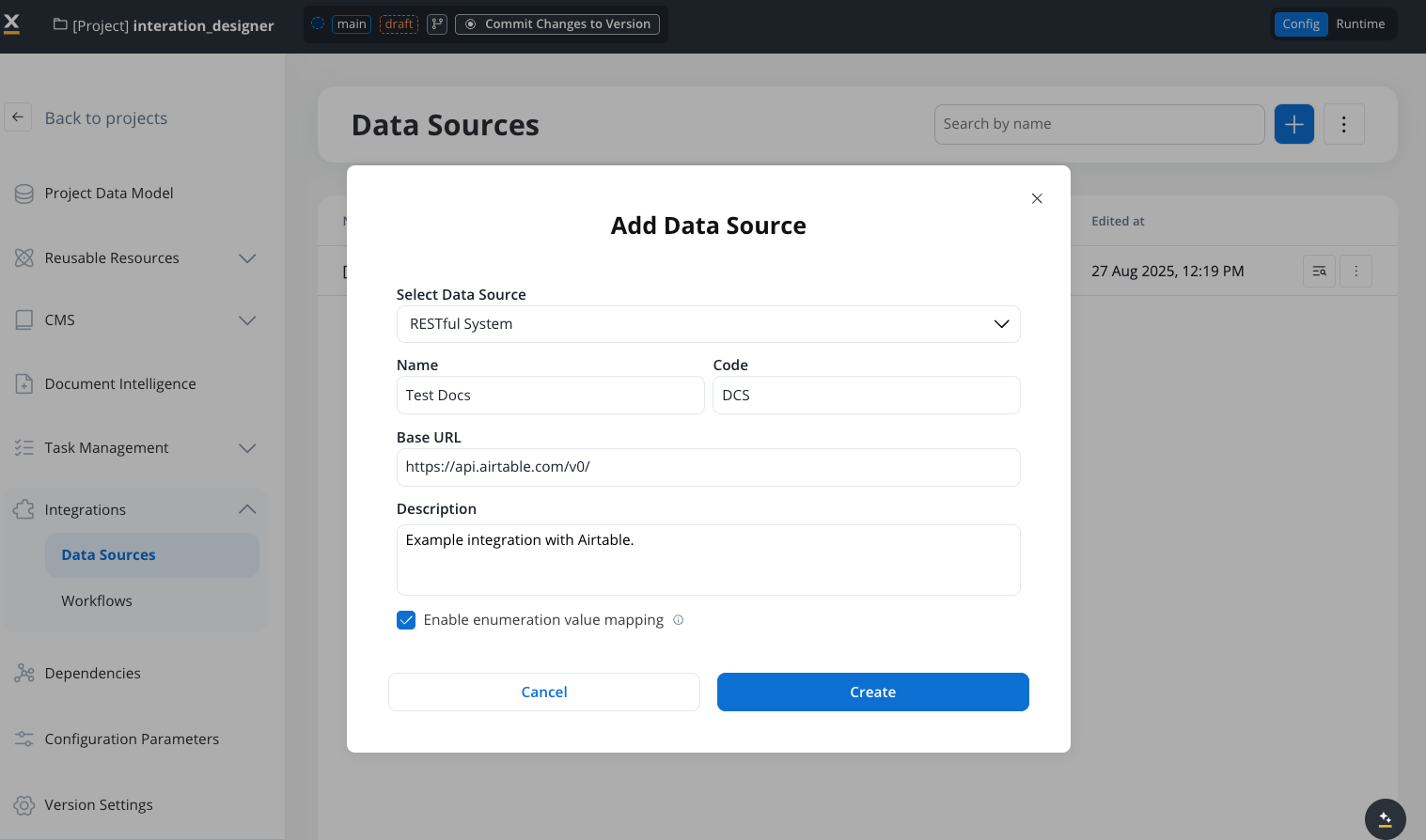
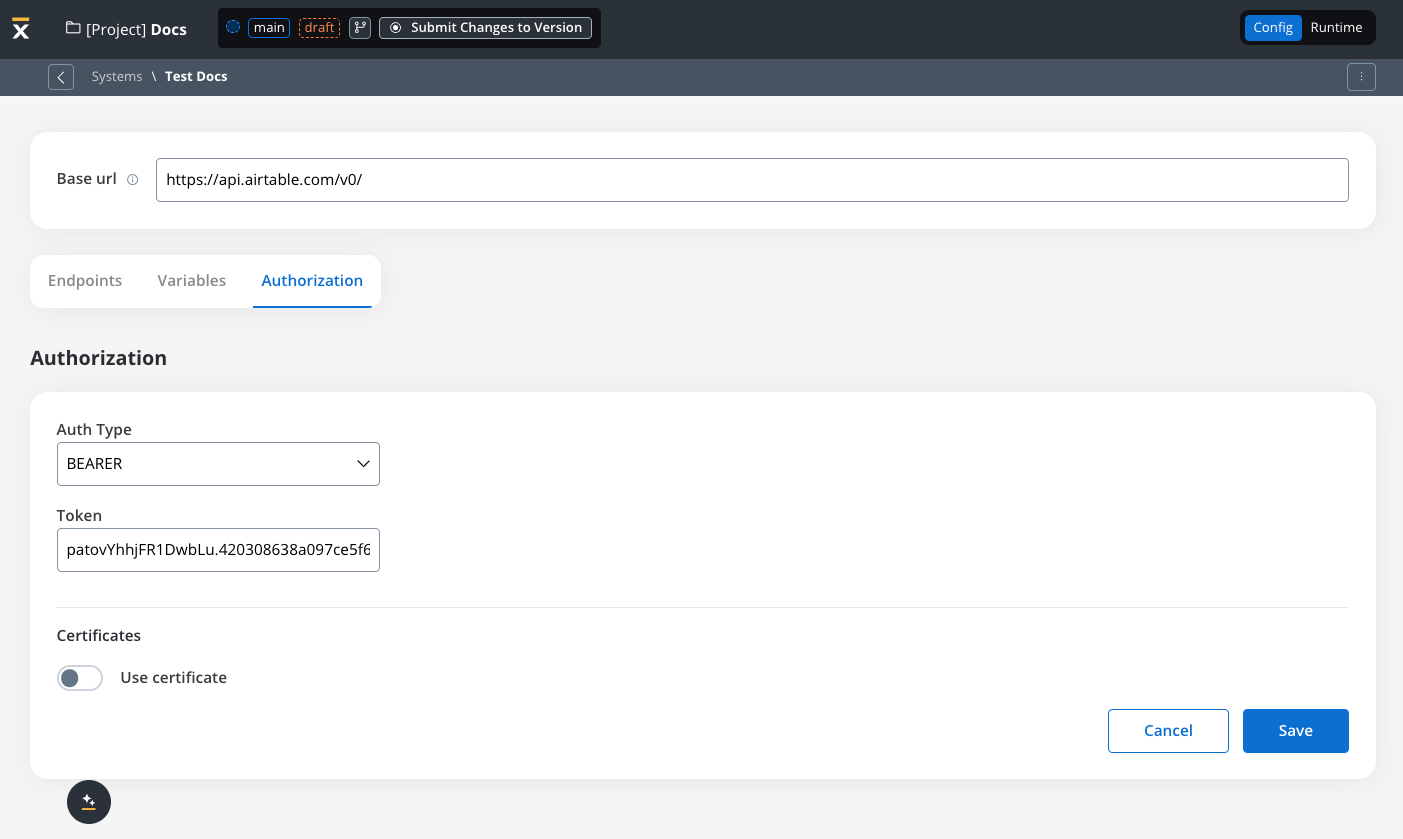
- Set up authorization (Service Token, Bearer Token, or No Auth). In our example, we will set the auth type as a bearer and we will set it at system level:
Defining REST integration endpoints
In this section you can define REST API endpoints that can be reused across different workflows.- Under the Endpoints section, add the necessary endpoints for system integration.
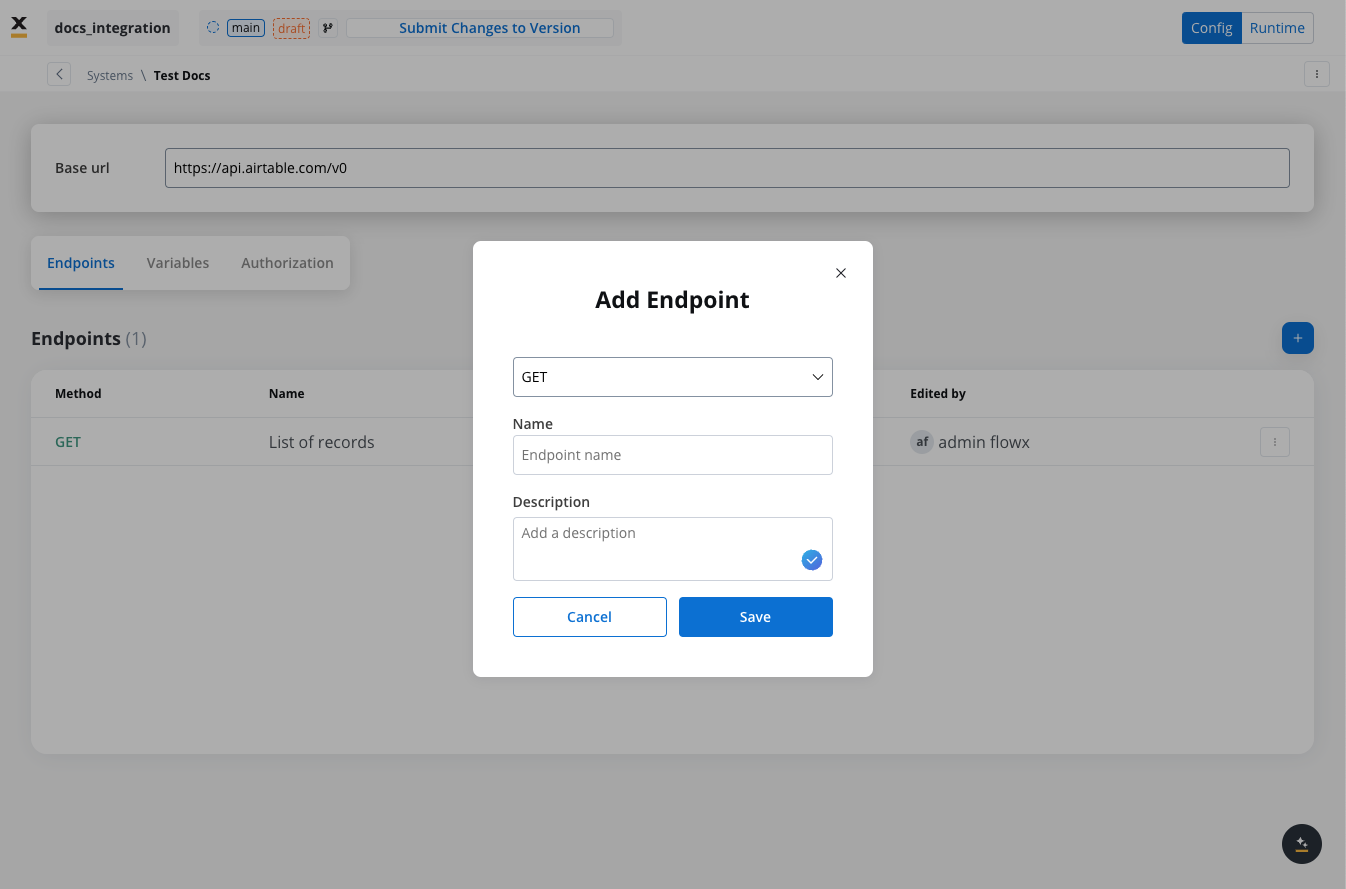
- Configure an endpoint by filling in the following properties:
- Method: GET, POST, PUT, PATCH, DELETE.
- Path: Path for the endpoint.
- Parameters: Path, query, and header parameters.
- Body: JSON, Multipart/form-data, or Binary.
- Response: JSON or Single binary file.
- Response example: Body or headers.
REST endpoint caching
Configuring cache Time-To-Live (TTL)
Choose between two TTL policies based on your use case:- Expires After (Duration-Based)
- Expires At (Time-Based)
- ISO Duration: Use ISO 8601 duration format
PT1H- Cache for 1 hourPT30M- Cache for 30 minutesP1D- Cache for 1 dayP1W- Cache for 1 week
- Dynamic Duration: Reference configuration parameters using
${myConfigParam} - Default:
R/P1D(1 day)
Cache visibility and management
Testing Modal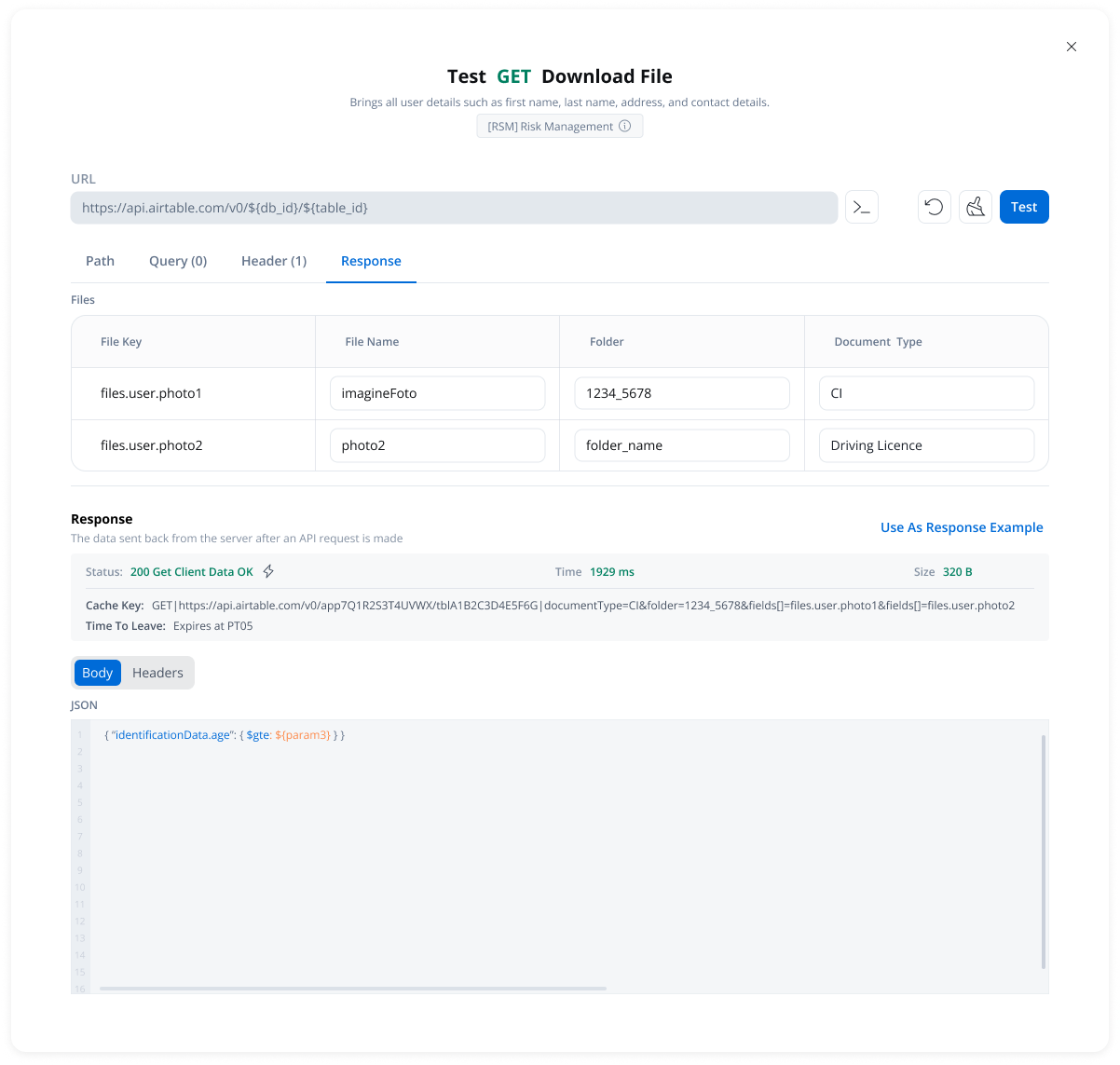
- Cache Status: Whether results came from cache (hit) or external API (miss)
- Cache Key: Unique identifier for the cached response
- TTL Information: When the cache will expire
- Duration-based: “Expires after PT10M” (10 minutes)
- Time-based: “Expires at 23:00 on 2025-11-04”
- Available in the endpoint testing modal
- Available from the endpoint definition page
- Only visible when caching is configured
How caching works
First Request
- Calls the external API
- Stores the response in cache with the configured TTL
- Returns the response to the workflow
Subsequent Requests
- FlowX.AI returns the cached response immediately
- No external API call is made
- Response time is significantly faster
Error handling
Automatic fallback scenarios:- Cache service unavailable → Direct API call
- Cache corruption or invalid data → Direct API call
- Cache storage failure → Direct API call (with warning logged)
Use cases
Reference Data
Rate Limit Compliance
Cost Optimization
Performance
Defining variables
The Variables tab allows you to store system-specific variables that can be referenced throughout workflows using the format${variableName}.
These declared variables can be utilized not only in workflows but also in other sections, such as the Endpoint or Authorization tabs.
- For our integration example, you can declare configuration parameters and use the variables to store your
tableIdandbaseIdand reference them the Variables tab.
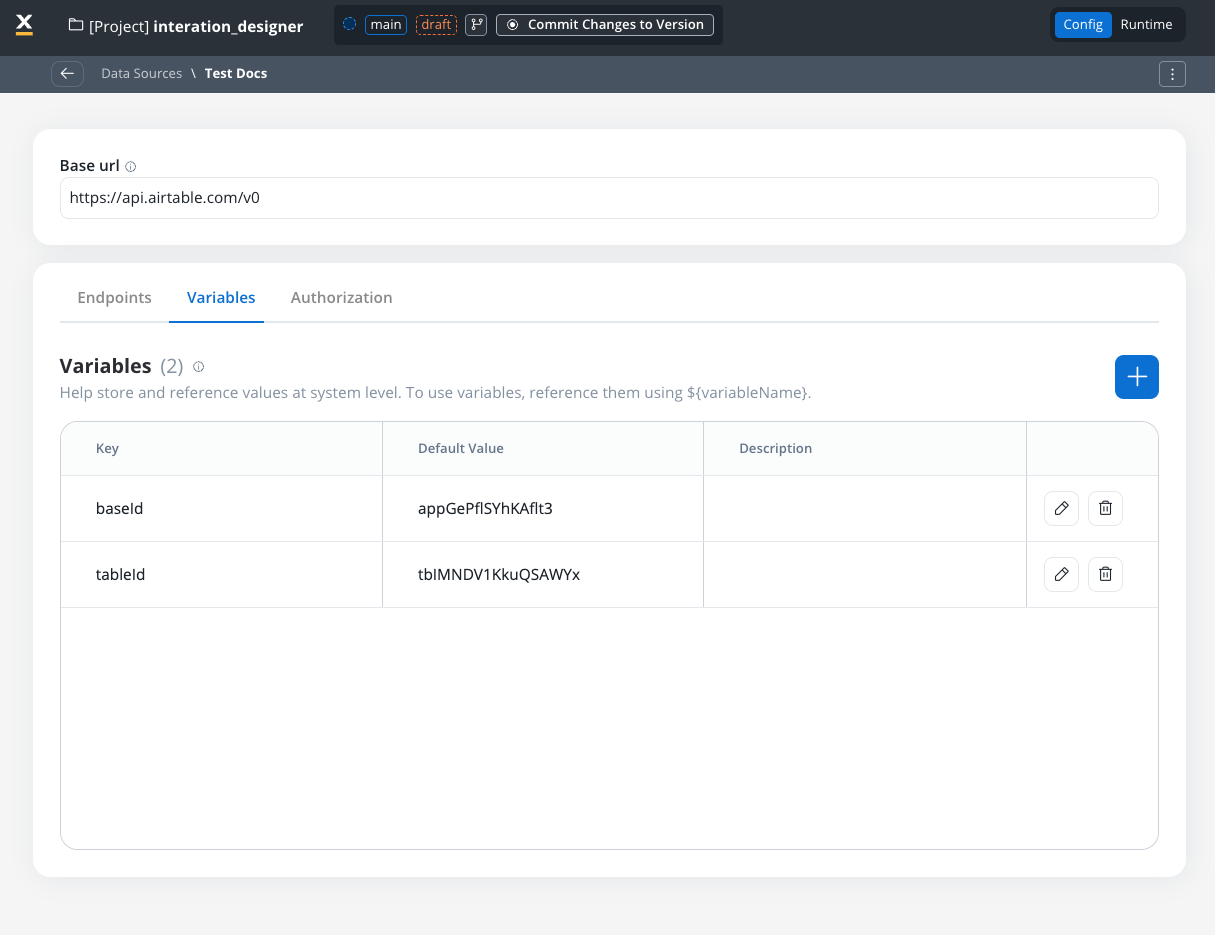
- Use variables in the Base URL to switch between different environments, such as UAT or production.
Endpoint parameter types
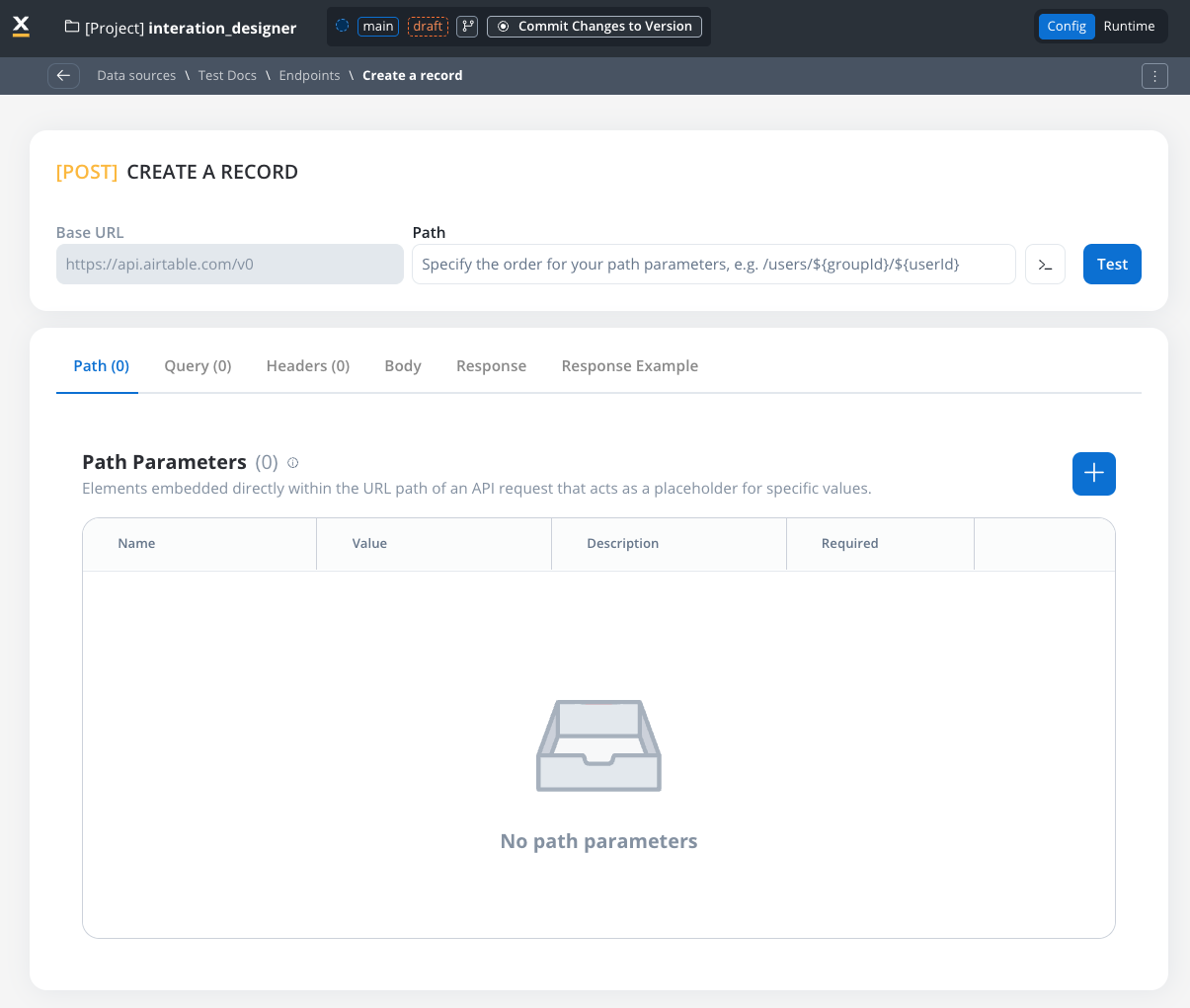
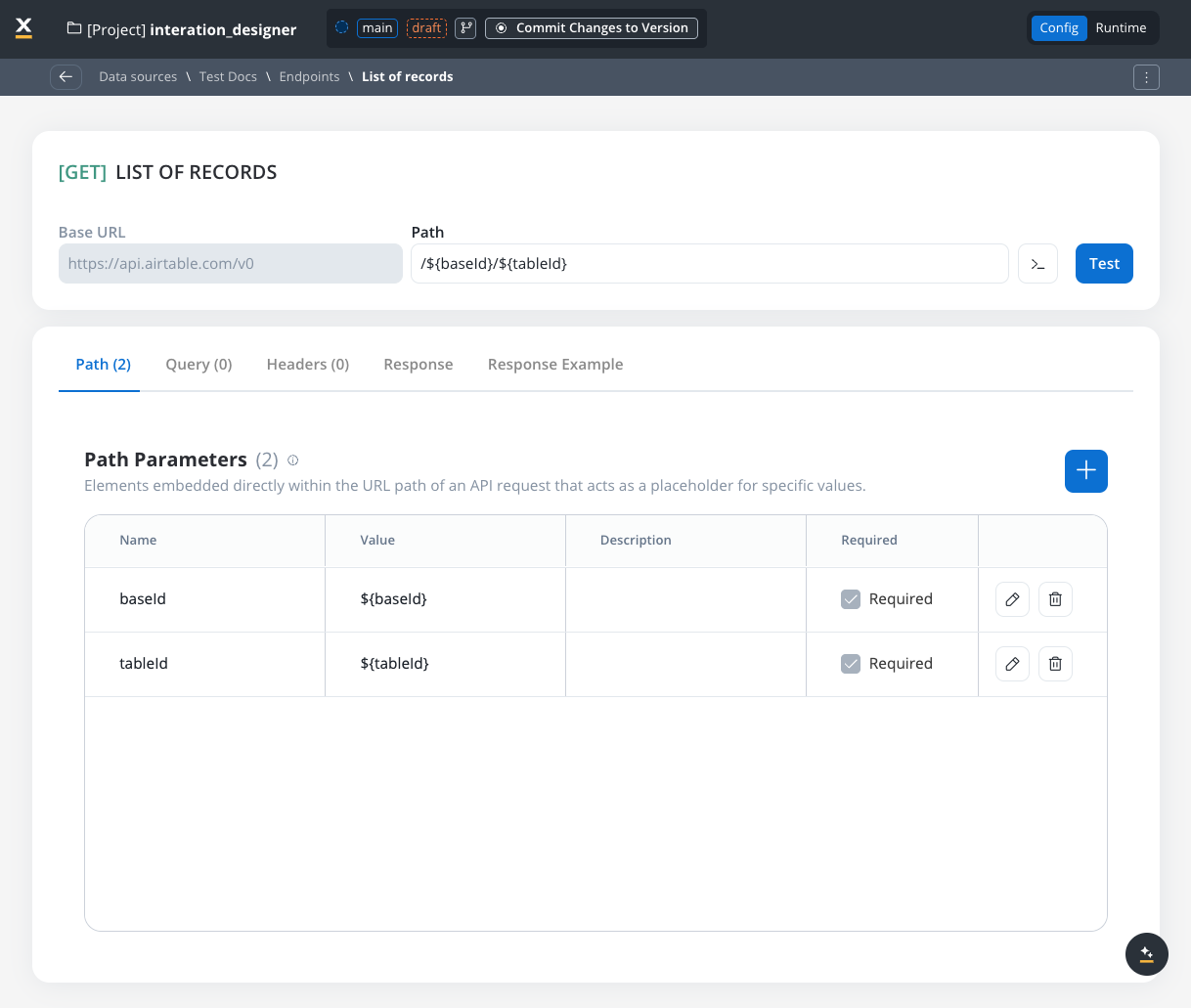
When configuring endpoints, several parameter types help define how the endpoint interacts with external systems. These parameters ensure that requests are properly formatted and data is correctly passed.Path parameters
Elements embedded directly within the URL path of an API request that acts as a placeholder for specific value.- Used to specify variable parts of the endpoint URL.
- Defined with
${parameter}format. - Mandatory in the request URL.
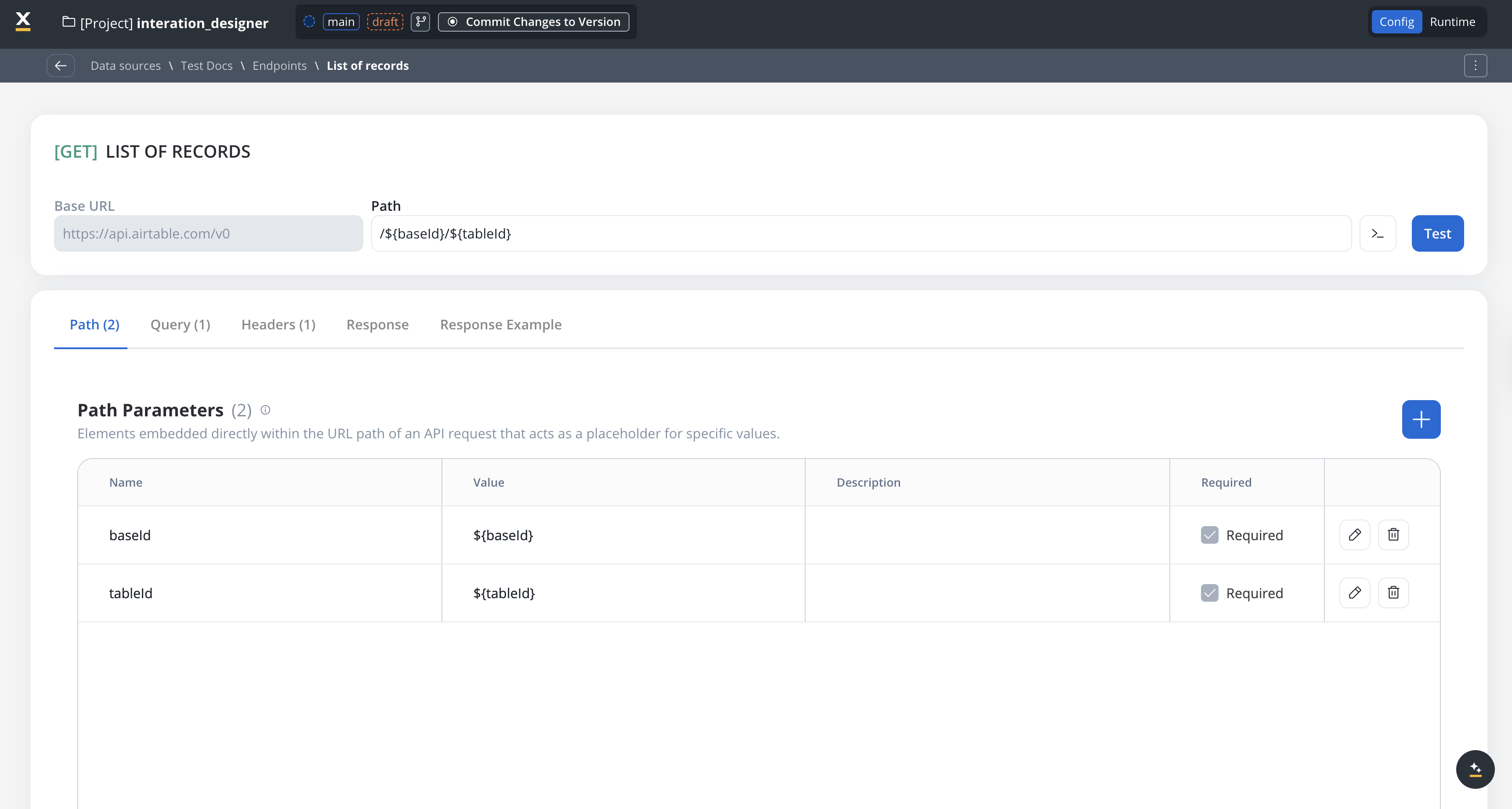
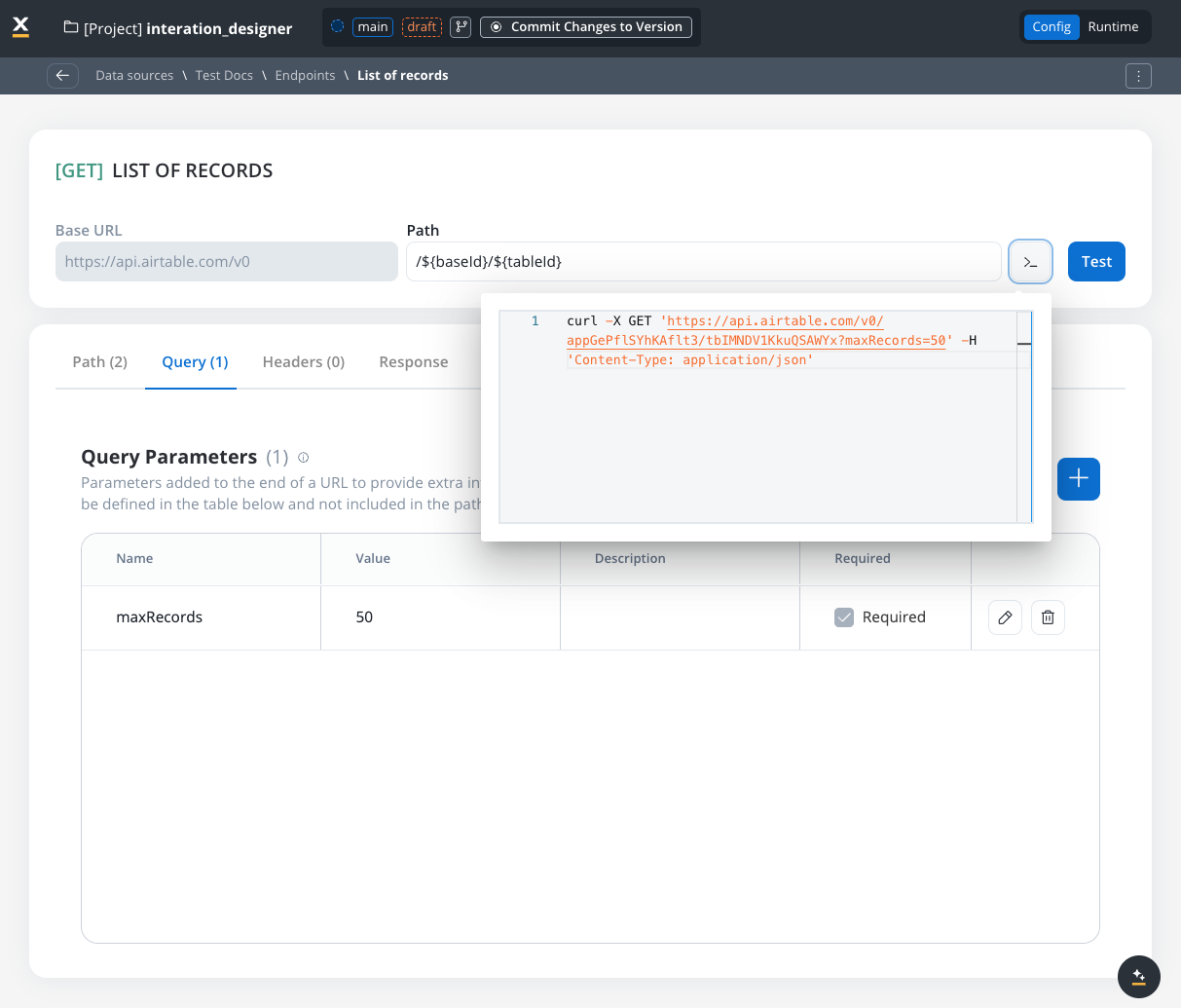
Query parameters
Query parameters are added to the end of a URL to provide extra information to a web server when making requests.- Query parameters are appended to the URL after a
?symbol and are typically used for filtering or pagination (for example,?search=value) - Useful for filtering or pagination.
- Example URL with query parameters: https://api.example.com/users?search=johndoe&page=2.
URL encoding option
Each query parameter has an Encode option that controls whether the value is URL-encoded before being sent:- Encode enabled: The system automatically URL-encodes the parameter value (special characters like spaces,
&,=are converted to their encoded equivalents like%20,%26,%3D) - Encode disabled (default): The value is sent as-is, allowing you to provide pre-encoded values
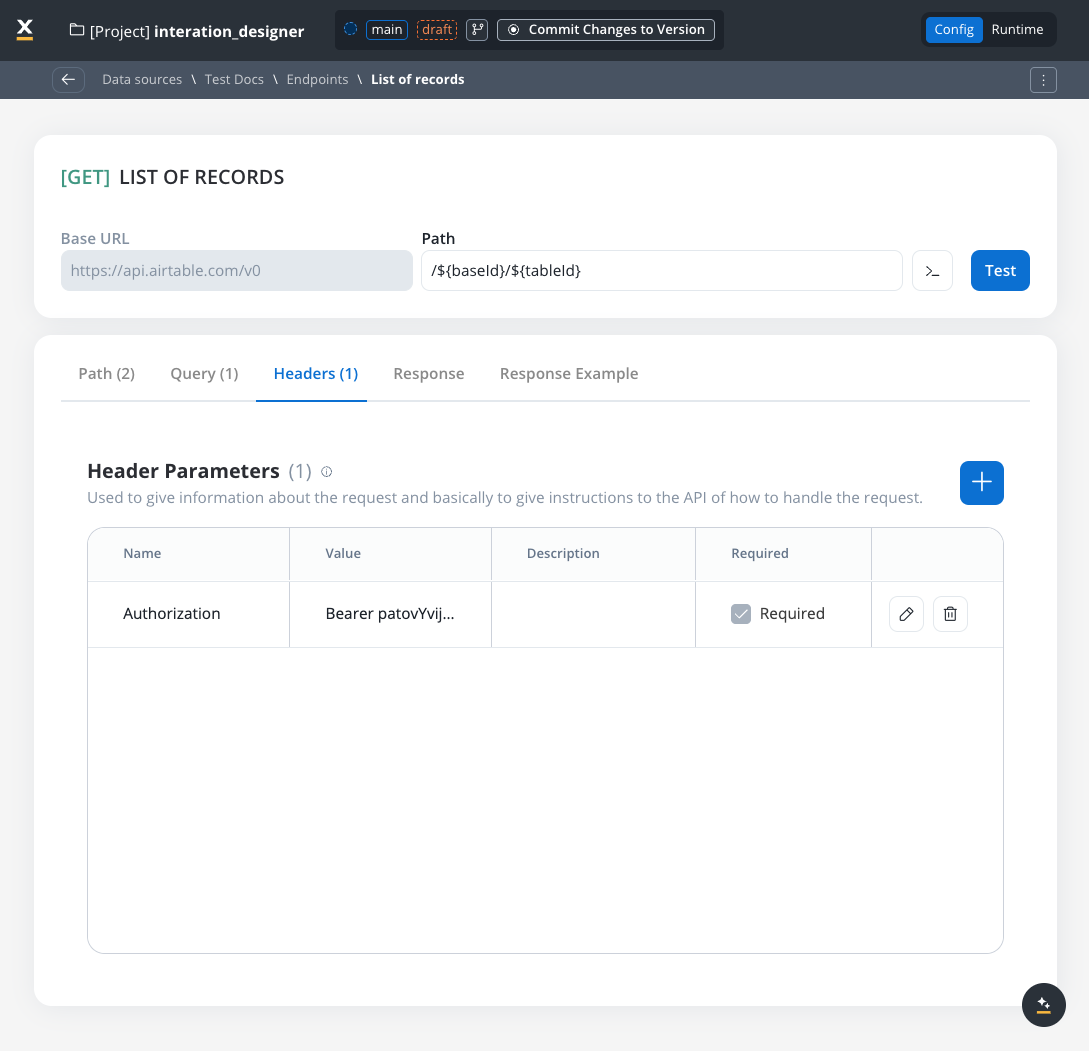
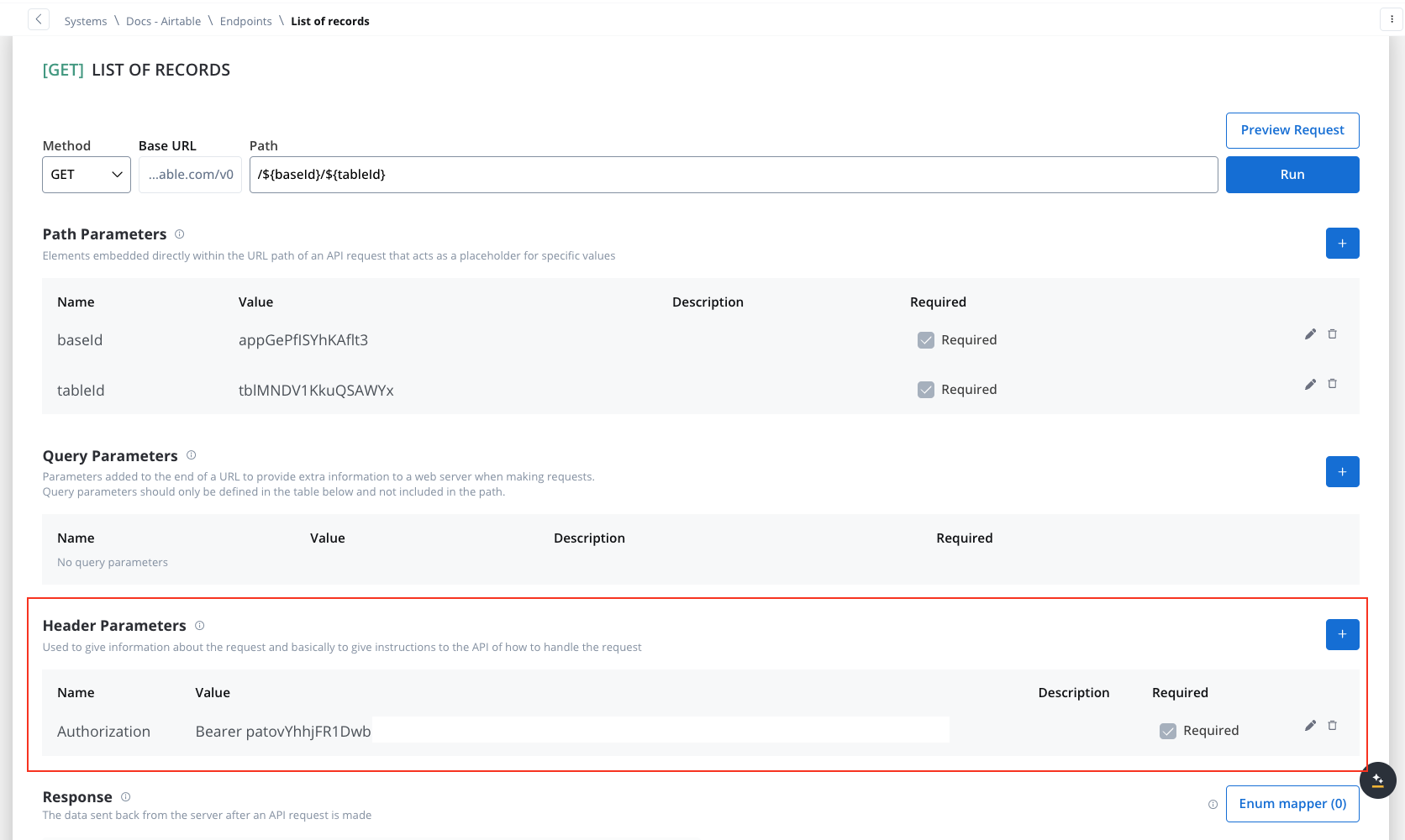
Header parameters
Used to give information about the request and to give instructions to the API of how to handle the request- Header parameters (HTTP headers) provide extra details about the request or its message body.
- They are not part of the URL. Default values can be set for testing and overridden in the workflow.
- Custom headers sent with the request (for example,
Authorization: Bearer token). - Define metadata or authorization details.
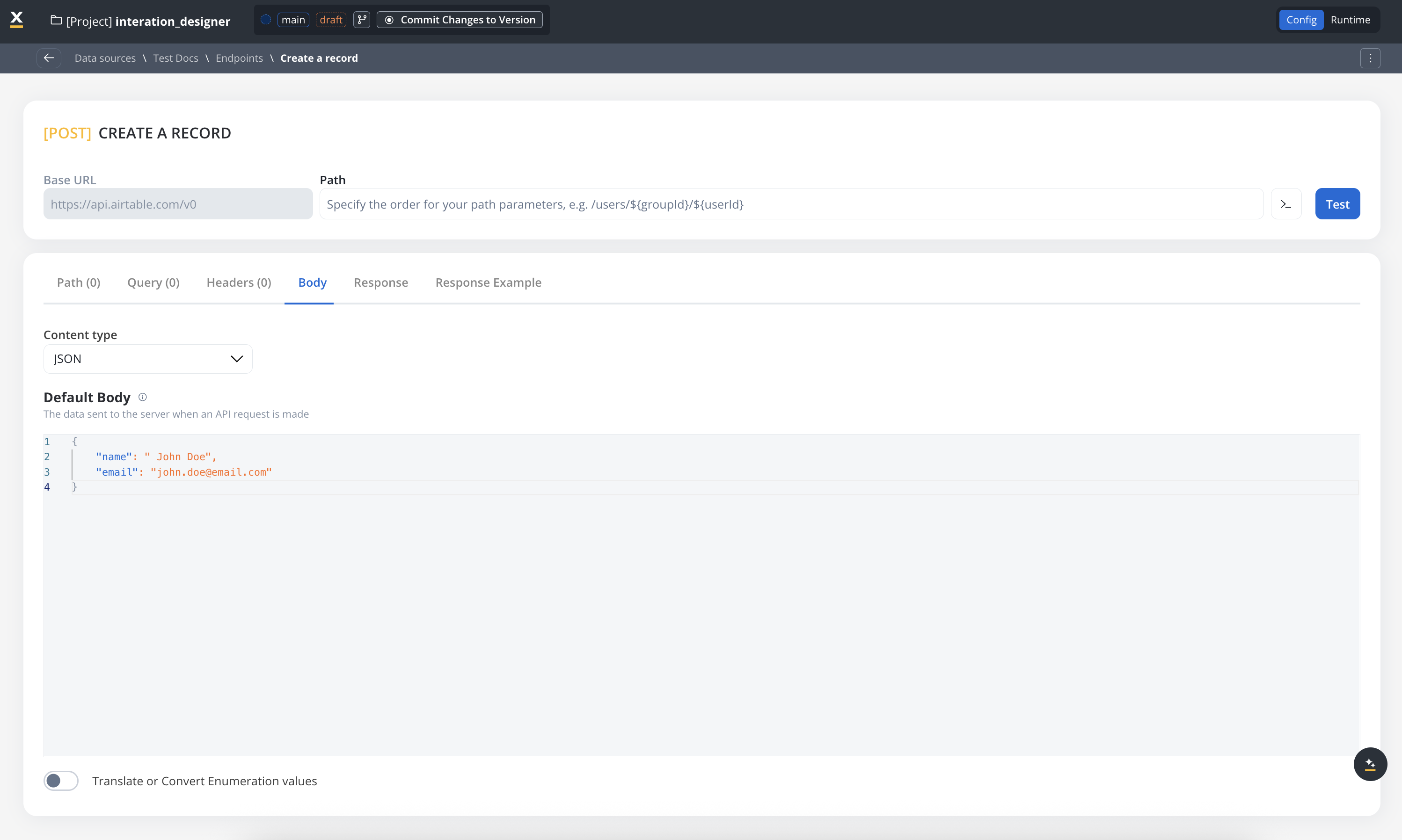
Body parameters
The data sent to the server when an API request is made.- These are the data fields included in the body of a request, usually in JSON format.
- Body parameters are used in POST, PUT, and PATCH requests to send data to the external system (for example, creating or updating a resource).
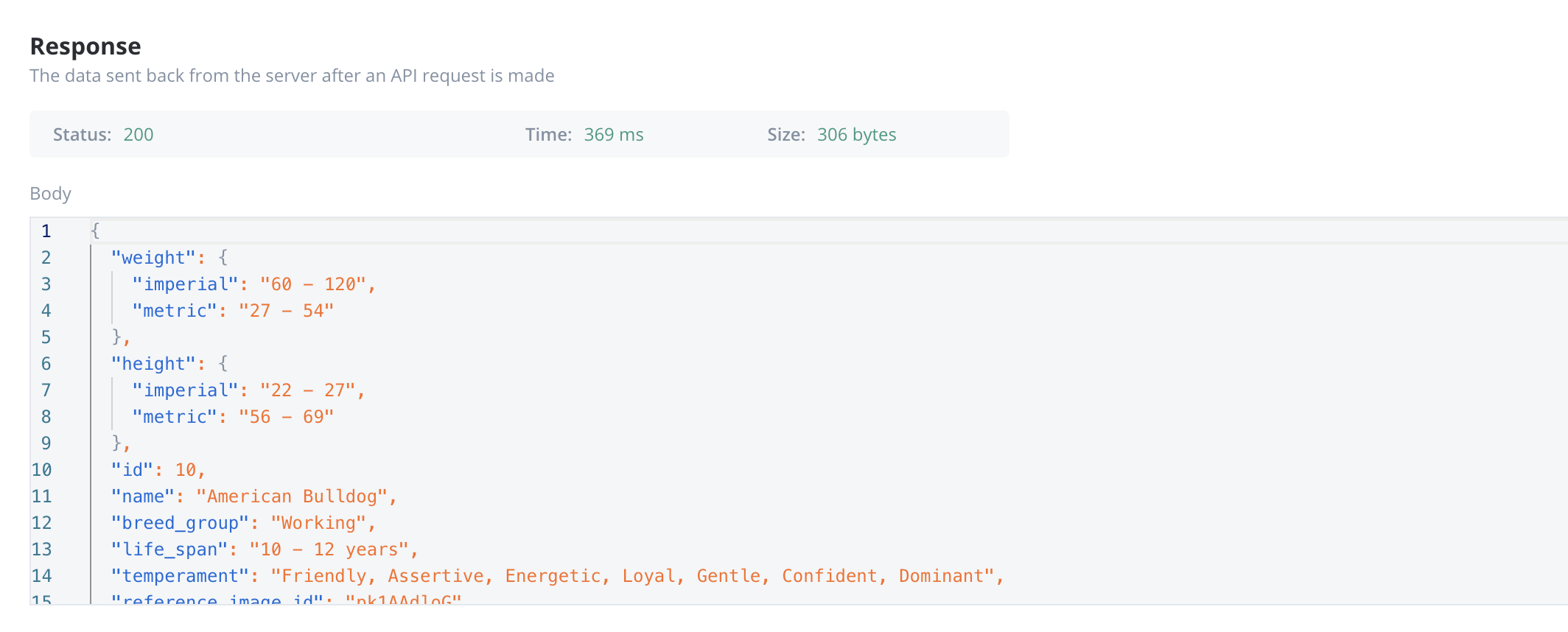
Response body parameters
The data sent back from the server after an API request is made.- These parameters are part of the response returned by the external system after a request is processed. They contain the data that the system sends back.
- Typically returned in GET, POST, PUT, and PATCH requests. Response body parameters provide details about the result of the request (for example, confirmation of resource creation, or data retrieval)
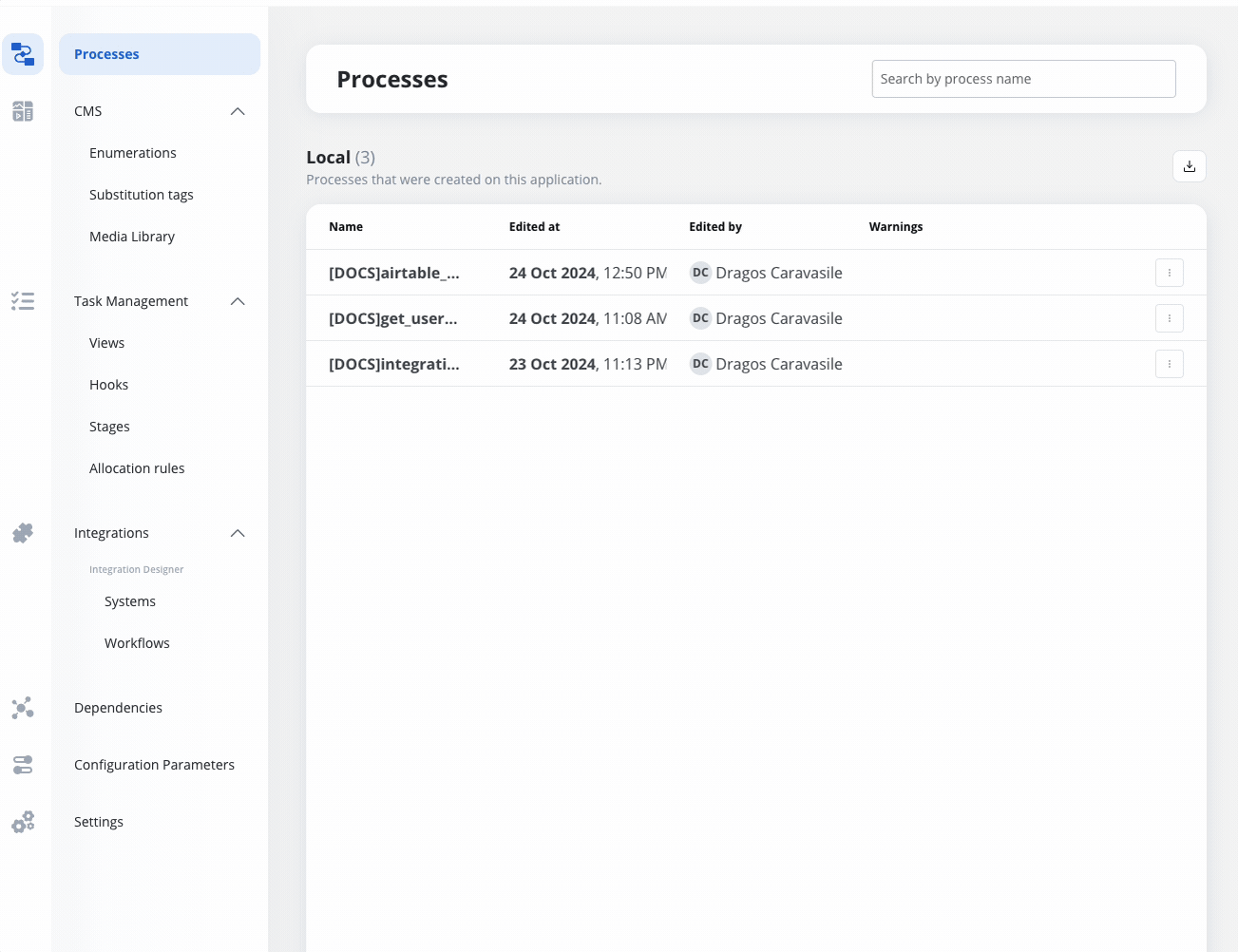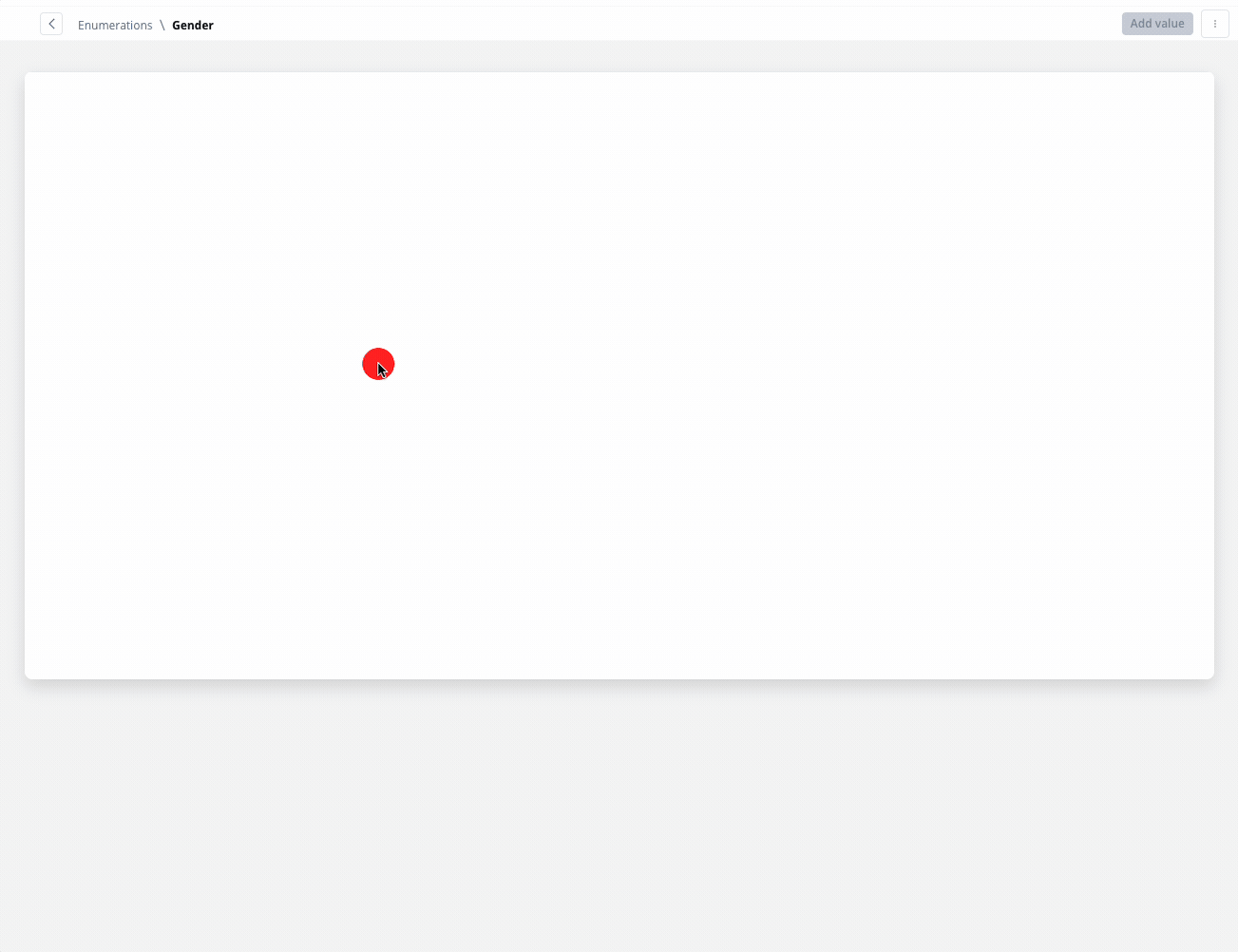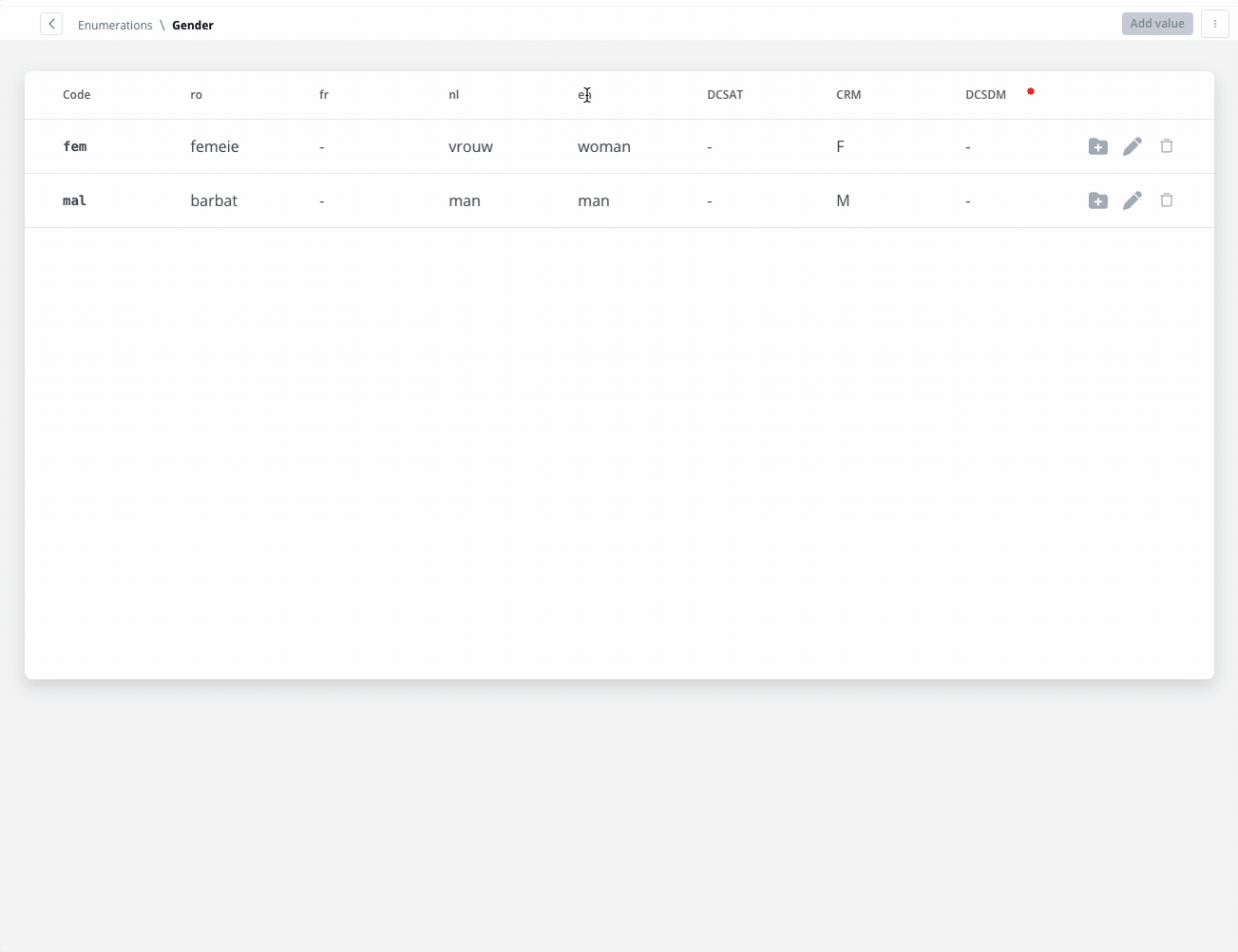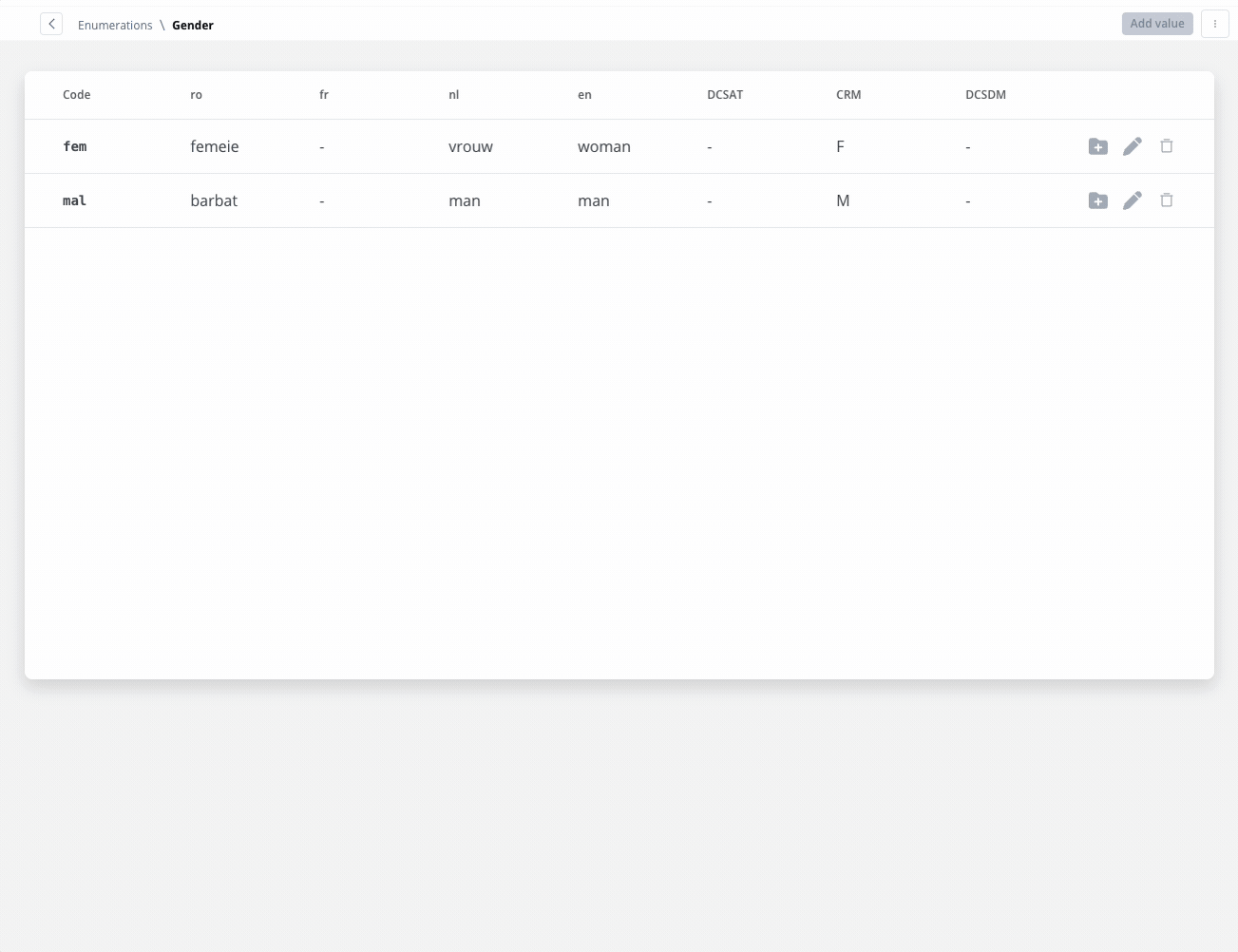
Enum mapper
The enum mapper for the request body enables you to configure enumerations for specific keys in the request body, aligning them with values from the External System or translations into another language.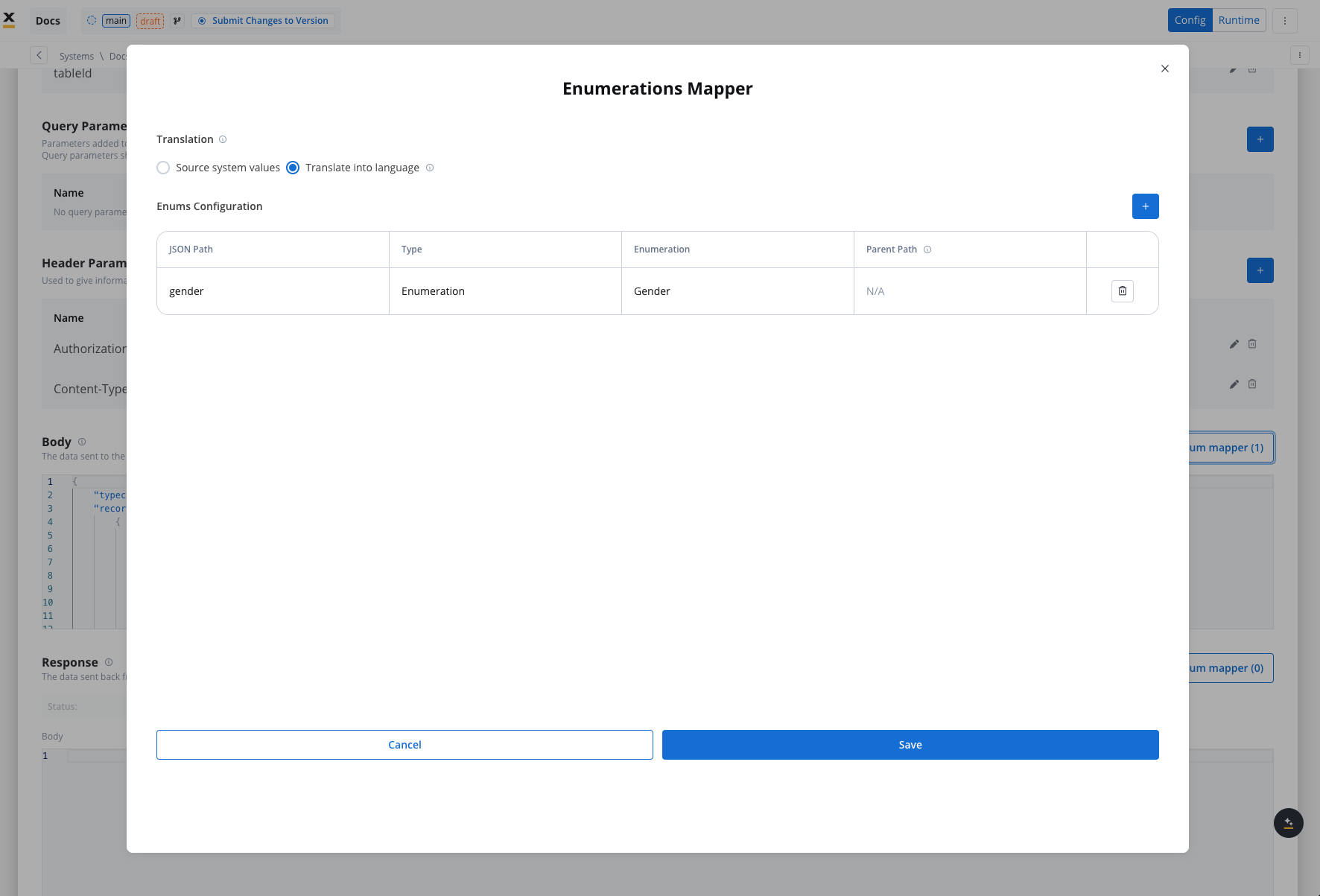
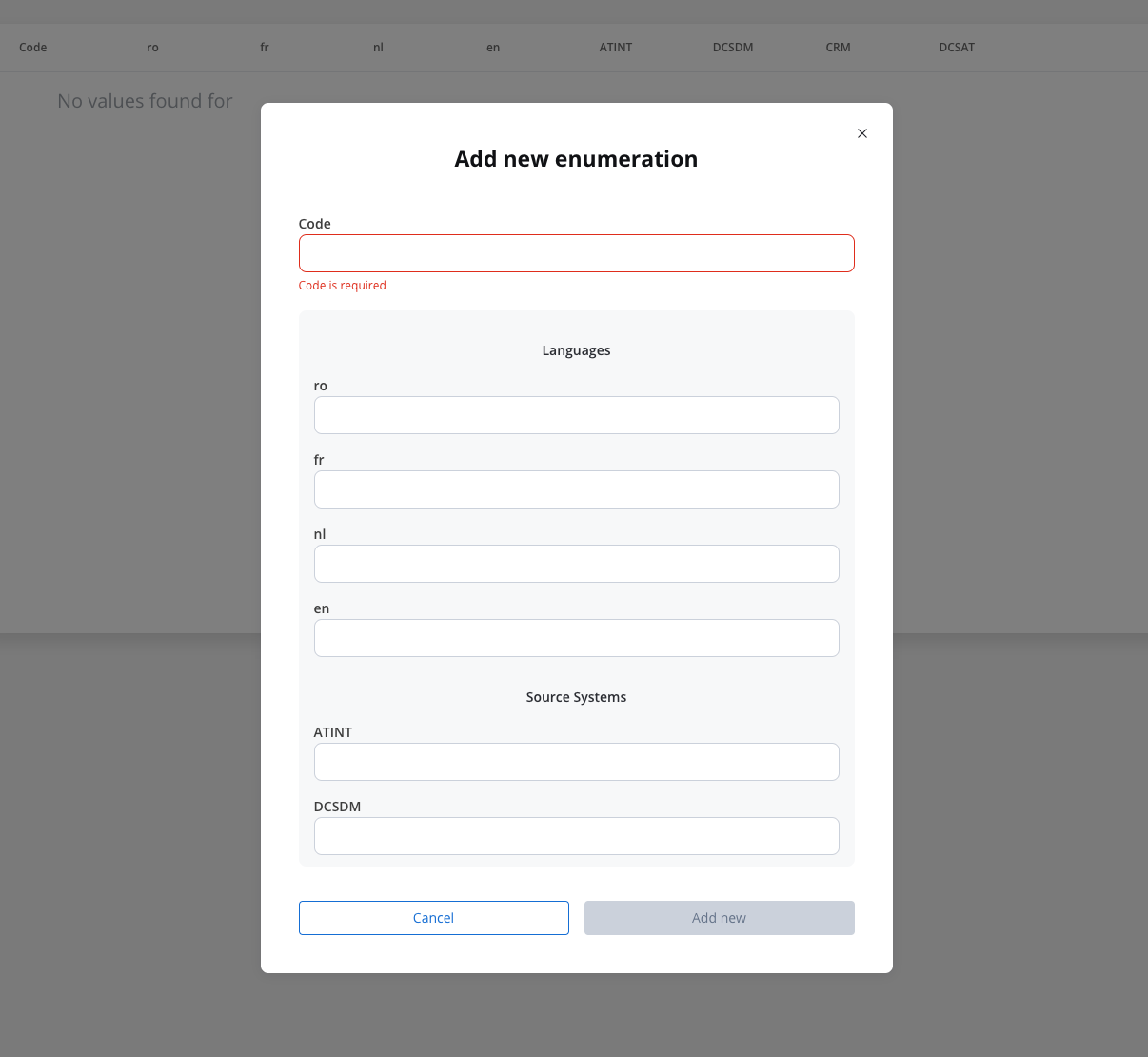
Configuring authorization
- Select the required Authorization Type from a predefined list.
- Enter the relevant details based on the selected type (for example, Realm and Client ID for Service Accounts).
- These details will be automatically included in the request headers when the integration is executed.
Authorization methods
The Integration Designer supports several authorization methods, allowing you to configure the security settings for API calls. Depending on the external system’s requirements, you can choose one of the following authorization formats: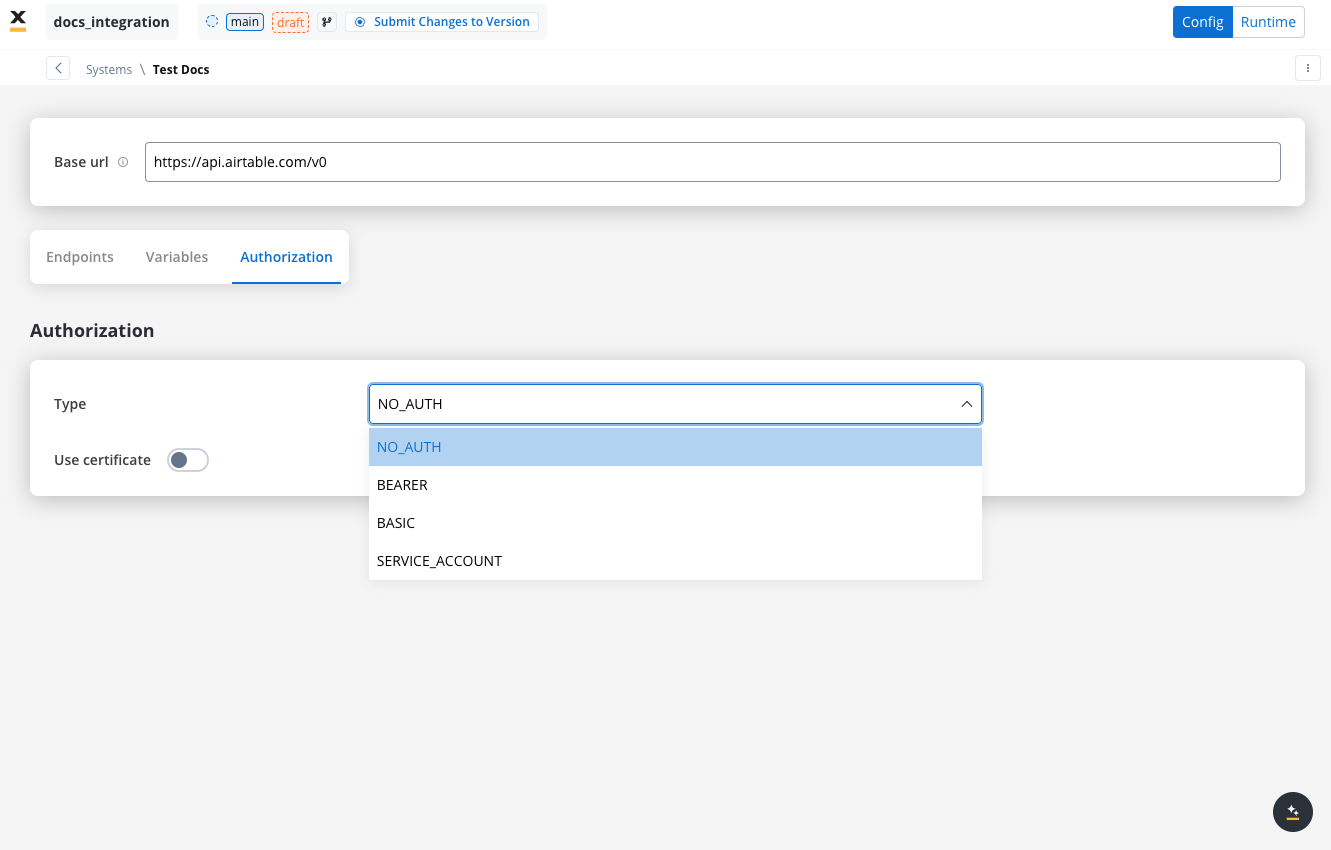
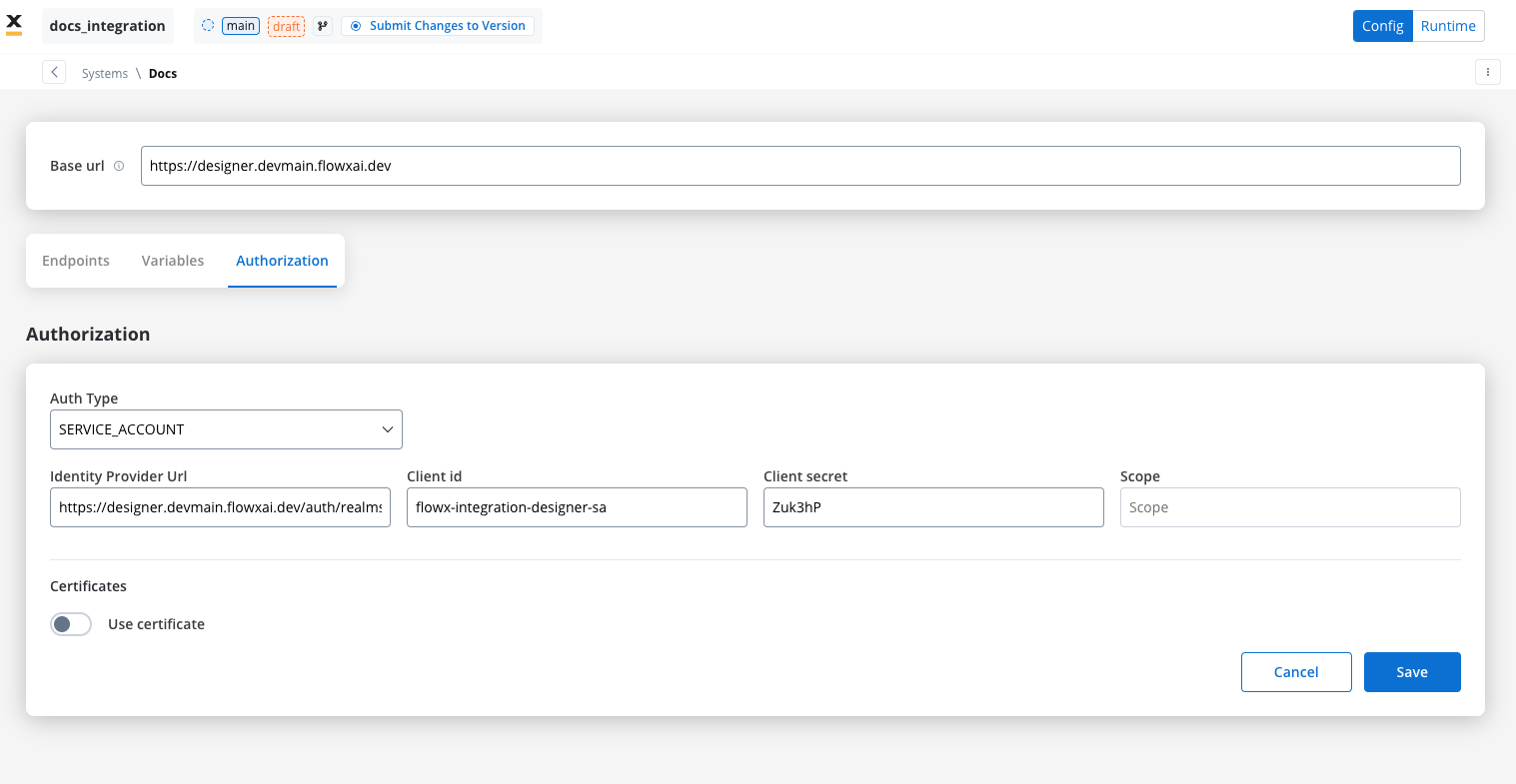
Service account
Service Account authentication requires the following key fields:- Identity Provider Url: The URL for the identity provider responsible for authenticating the service account.
- Client Id: The unique identifier for the client within the realm.
- Client secret: A secure secret used to authenticate the client alongside the Client ID.
- Scope: Specifies the access level or permissions for the service account.
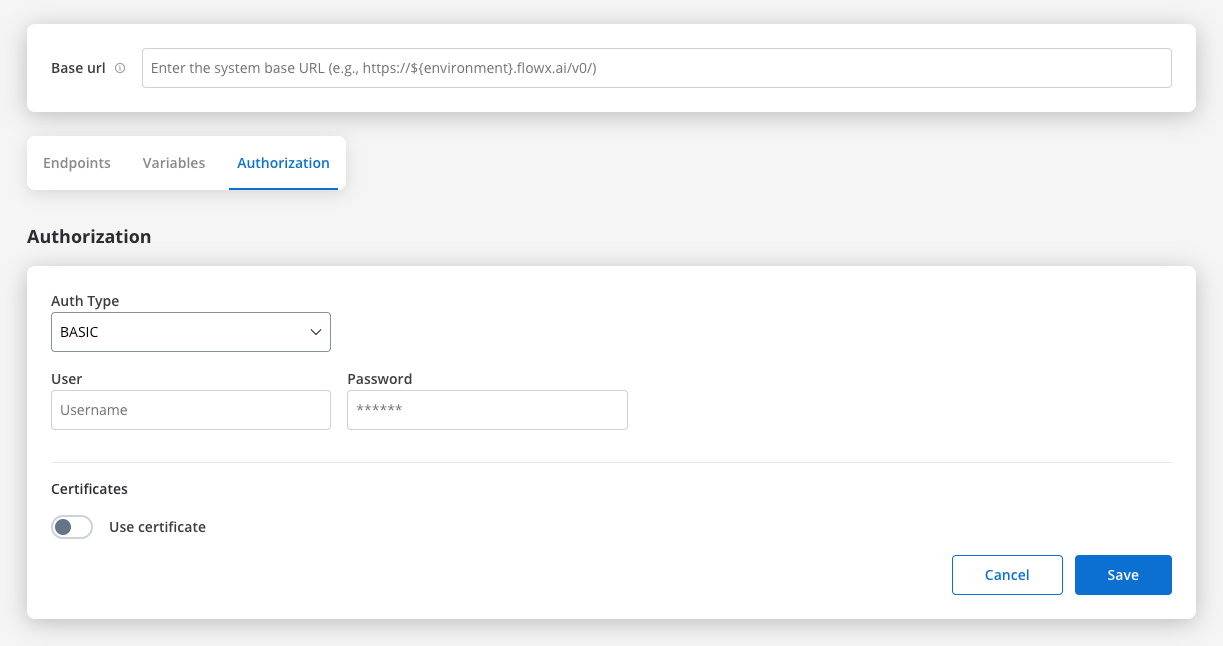
Basic authentication
- Requires the following credentials:
- Username: The account’s username.
- Password: The account’s password.
- Suitable for systems that rely on simple username/password combinations for access.
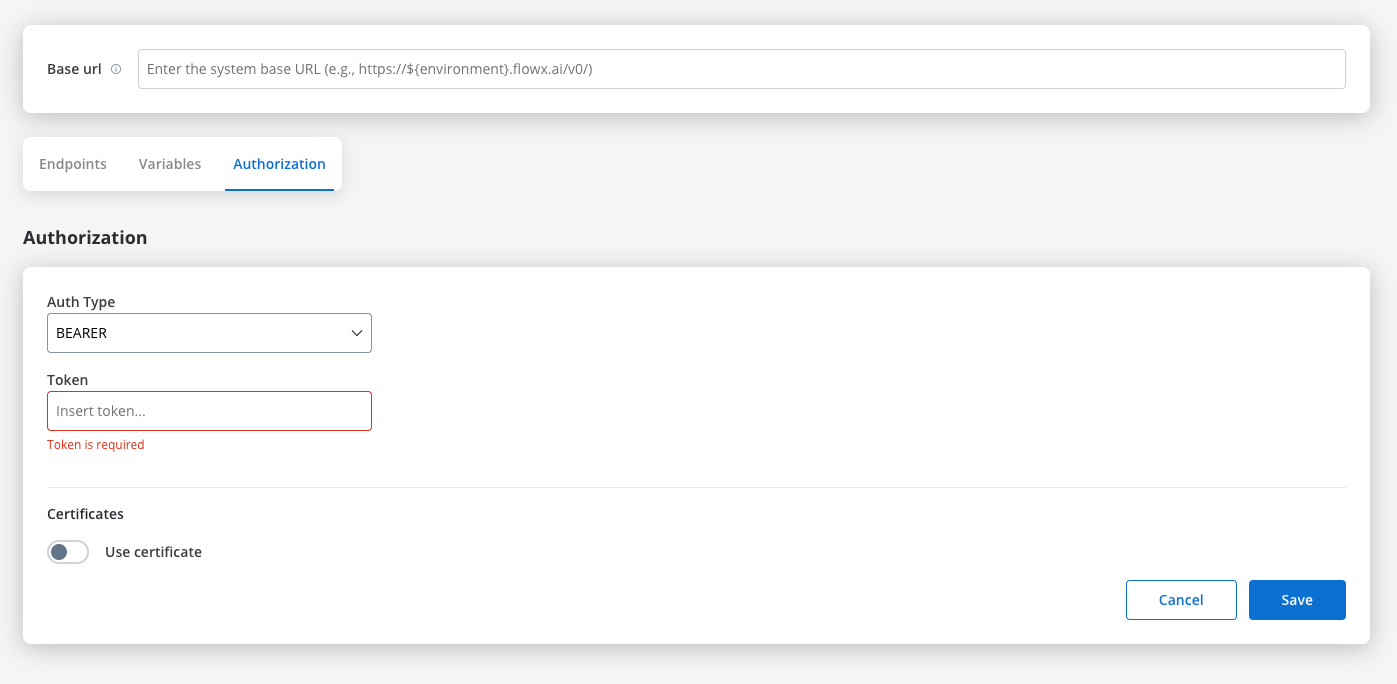
Bearer
- Requires an Access Token to be included in the request headers.
- Commonly used for OAuth 2.0 implementations.
- Header Configuration: Use the format
Authorization: Bearer {access_token}in headers of requests needing authentication.
- System-Level Example: You can store the Bearer token at the system level, as shown in the example below, ensuring it’s applied automatically to future API calls:
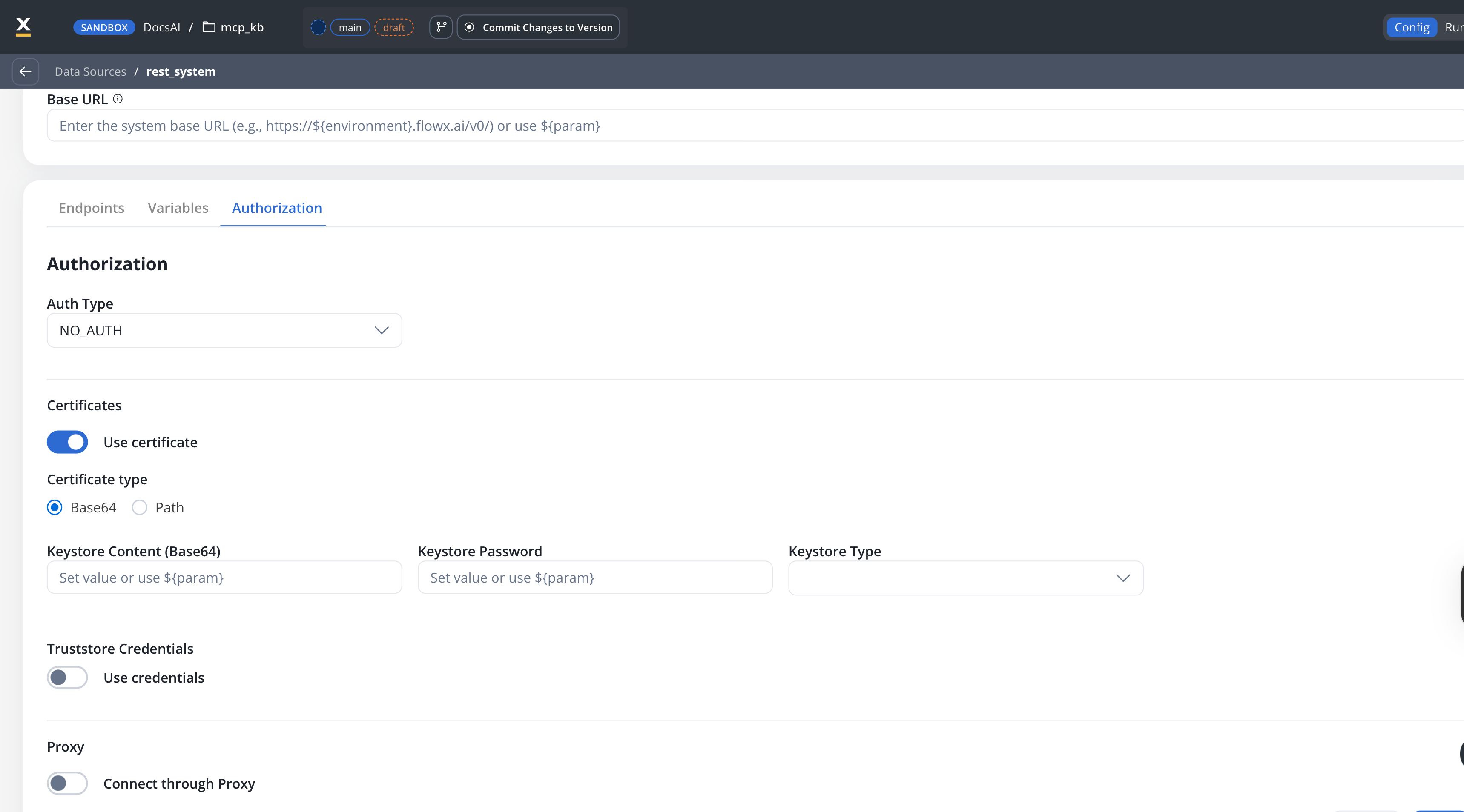
Certificates
Use this setup to configure secure communication with external systems that require certificates. It includes a Keystore (which holds the client certificate) and a Truststore (which holds trusted certificates). You can toggle these features based on the security requirements of the integration.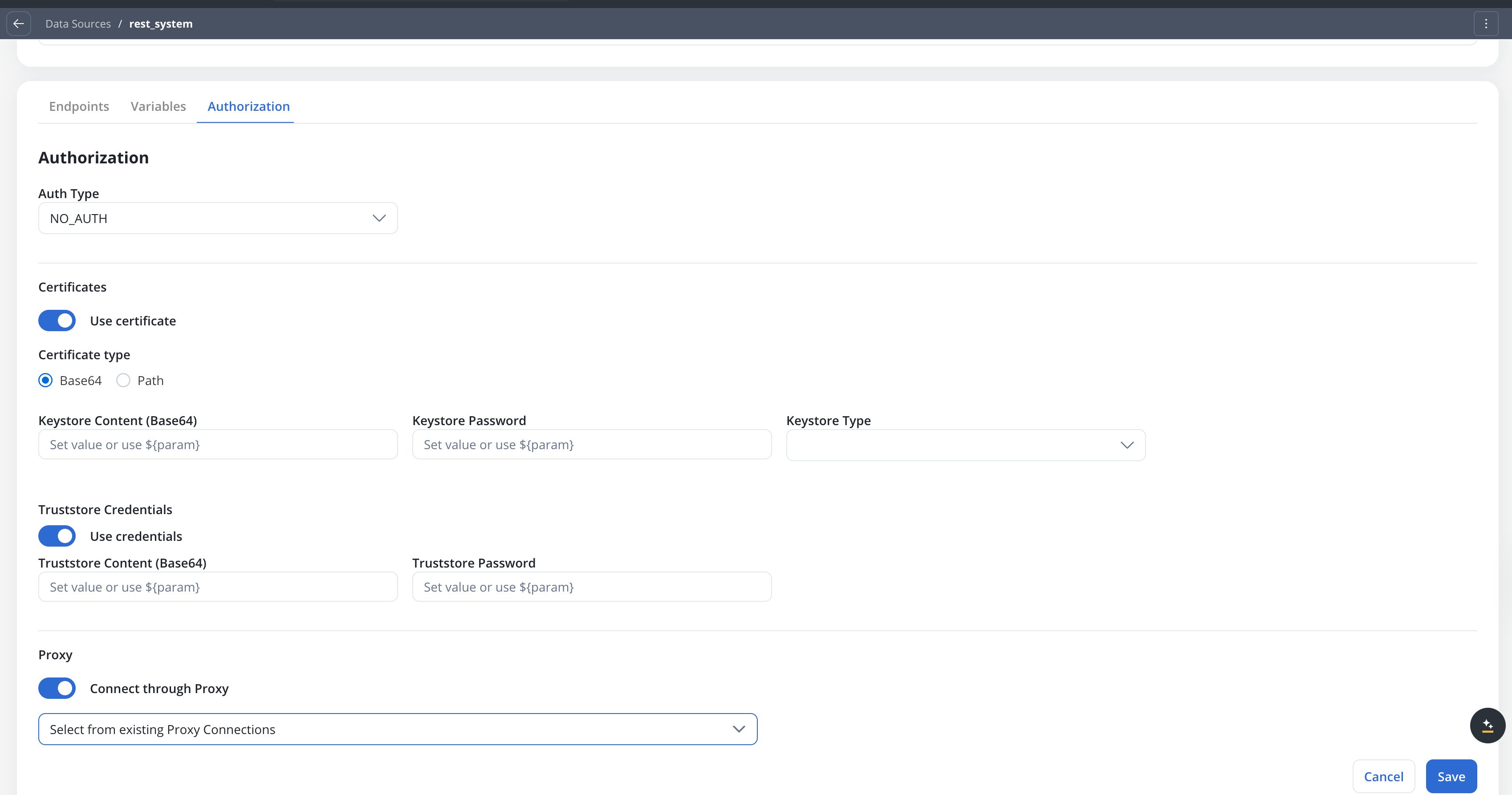
${configParam} syntax).- Base64 (default for new configurations) — provide the certificate content directly as a base64-encoded string
- Path — provide the file system path to the certificate file
| Field | Base64 mode | Path mode |
|---|---|---|
| Keystore Content (Base64) | Base64-encoded keystore content | — |
| Keystore Path | — | File path, e.g., /opt/certificates/testkeystore.jks |
| Keystore Password | Password to unlock the keystore | Password to unlock the keystore |
| Keystore Type | JKS or PKCS12 | JKS or PKCS12 |
| Field | Base64 mode | Path mode |
|---|---|---|
| Truststore Content (Base64) | Base64-encoded truststore content | — |
| Truststore Path | — | File path, e.g., /opt/certificates/testtruststore.jks |
| Truststore Password | Password to access the truststore | Password to access the truststore |
${configParam} placeholders for dynamic per-environment resolution.
File handling
You can now handle file uploads and downloads with external systems directly within Integration Designer. This update introduces native support for file transfers in RESTful connectors, reducing the need for custom development and complex workarounds.Core scenarios
Integration Designer supports two primary file handling scenarios:Downloading Files
GET or POST) and receives a response containing one or more files. Integration Designer saves these files to a specified location and returns their new paths to the workflow for further processing.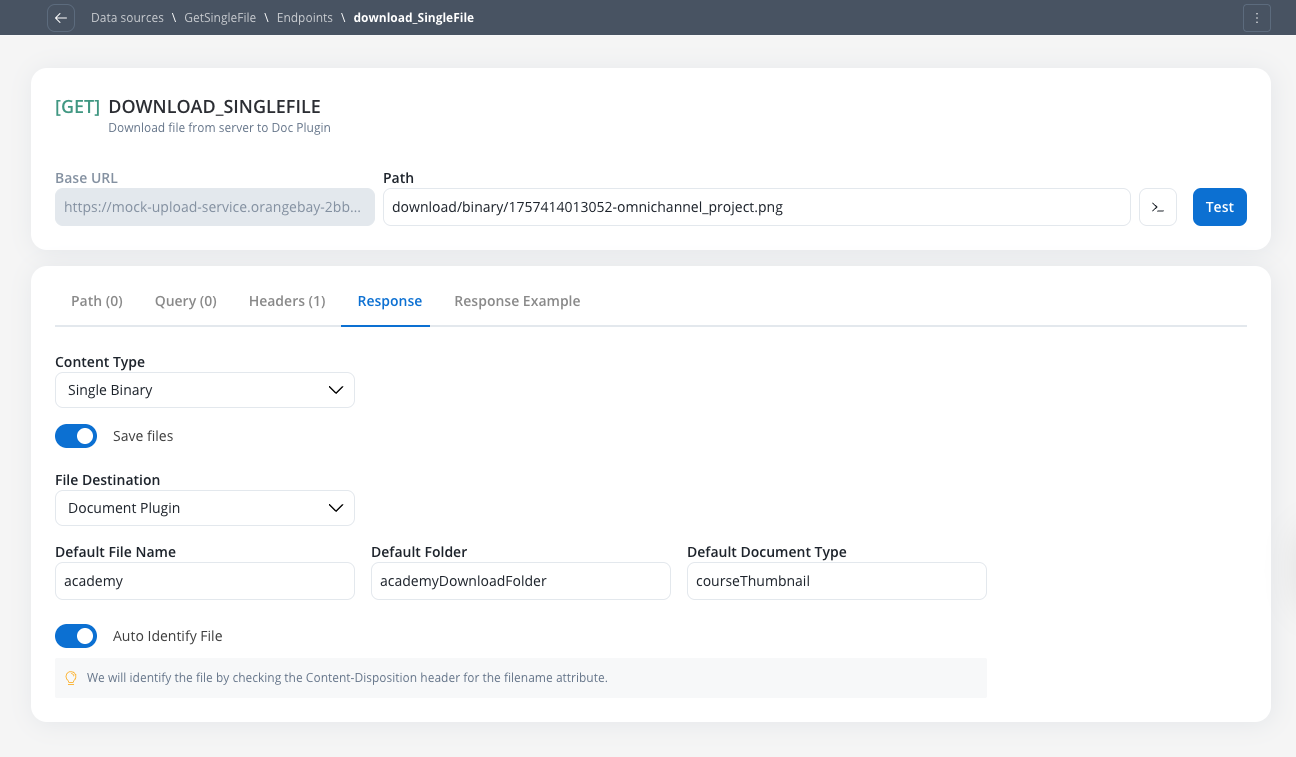
Receiving files (endpoint response configuration)
To configure an endpoint to handle incoming files from an external system, navigate to its Response tab. This functionality is available for bothGET and POST methods.
Enabling and configuring file downloads
Activate File Processing
Handling JSON content-type
This option is used when the API returns a JSON object containing one or more Base64 encoded files. File Destination Configuration:- Document Plugin
- S3 Protocol
${processInstanceId} to be mapped dynamically at runtime.| Column | Description | Example |
|---|---|---|
| Base 64 File Key | The JSON path to the Base64 encoded string | files.user.photo |
| File Name Key | Optional. The JSON path to the filename string | files.photoName |
| Default File Name | A fallback name to use if the File Name Key is not found | imagineProfil |
| Default Folder | The business-context folder, such as a client ID (CNP) | folder_client |
| Default Doc Type | The document type for classification in the Document Plugin | Carte Identitate |
Translate or Convert Enumeration Values toggle can be used in conjunction with the Save Files feature.Handling Single Binary content-type
This option is used when the entire API response body is the file itself. The Single Binary content-type is ideal for endpoints that return raw file data directly in the response body.Configure Content-Type
- Enable the Save Files toggle
- Select Single Binary from the Content-Type dropdown
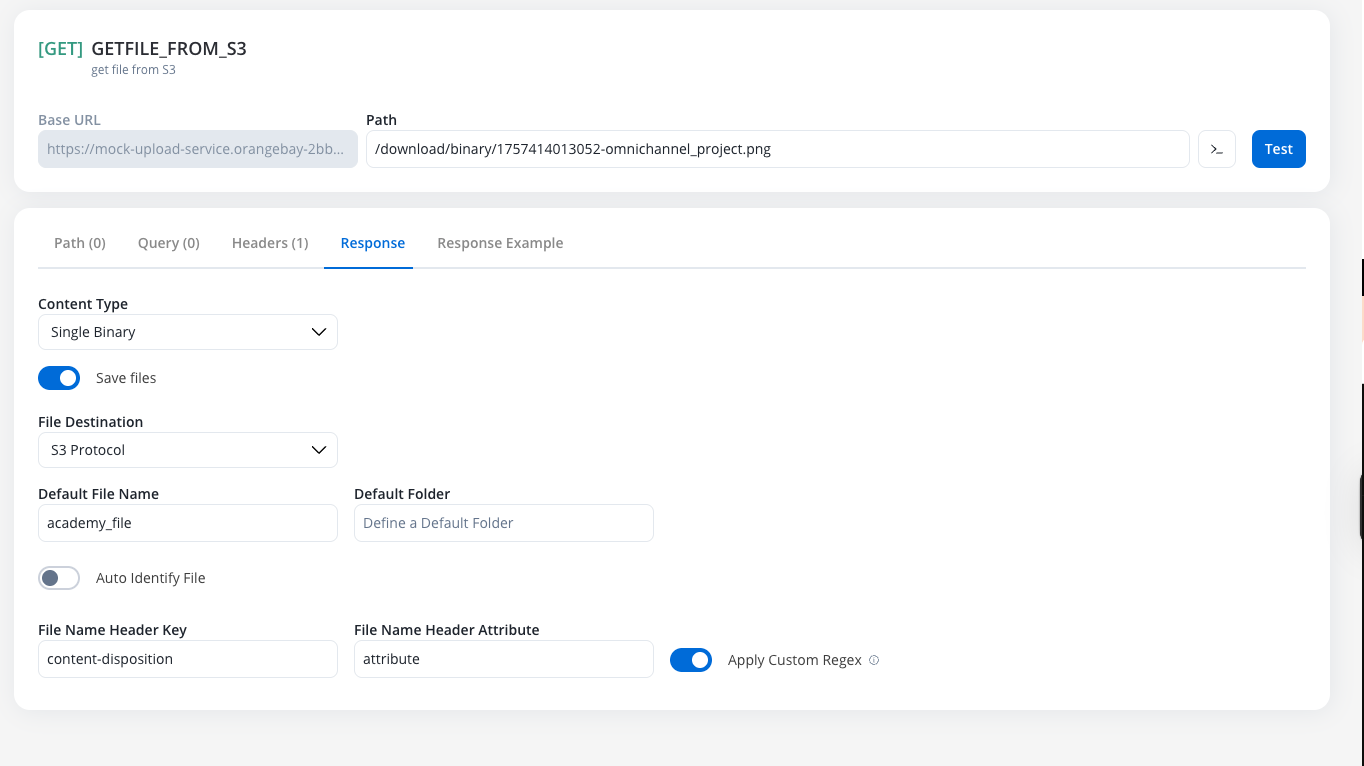
Choose File Destination
- S3 Protocol
- Document Plugin
- Auto Identify (Recommended)
- Manual Configuration
Content-Disposition HTTP header to extract the filename attribute. This is the standard approach for most file download endpoints.Content-Disposition header.document.pdf as the filename.- Document Plugin
- S3 Protocol
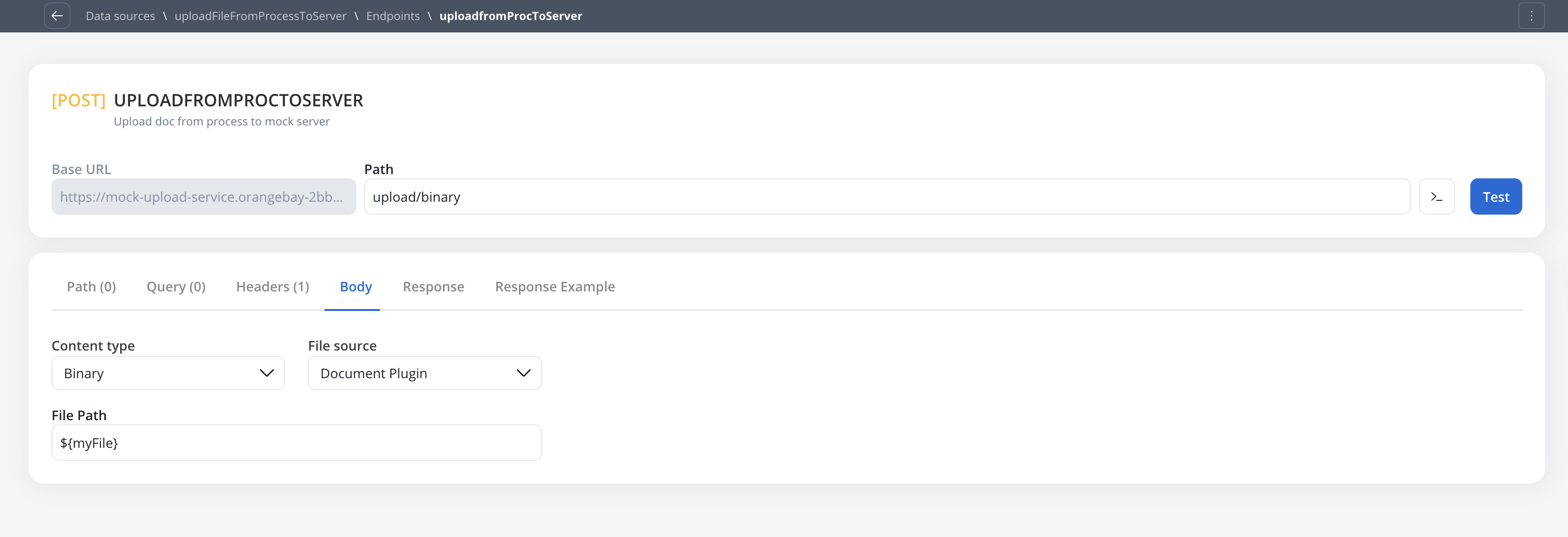
Sending files (endpoint POST body configuration)
To configure an endpoint to send a file, navigate to the Body tab and select the appropriate Content Type.Content Type: Multipart/Form-data
Use this to send files and text fields in a single request. This format is flexible and can handle mixed content types within the same POST request.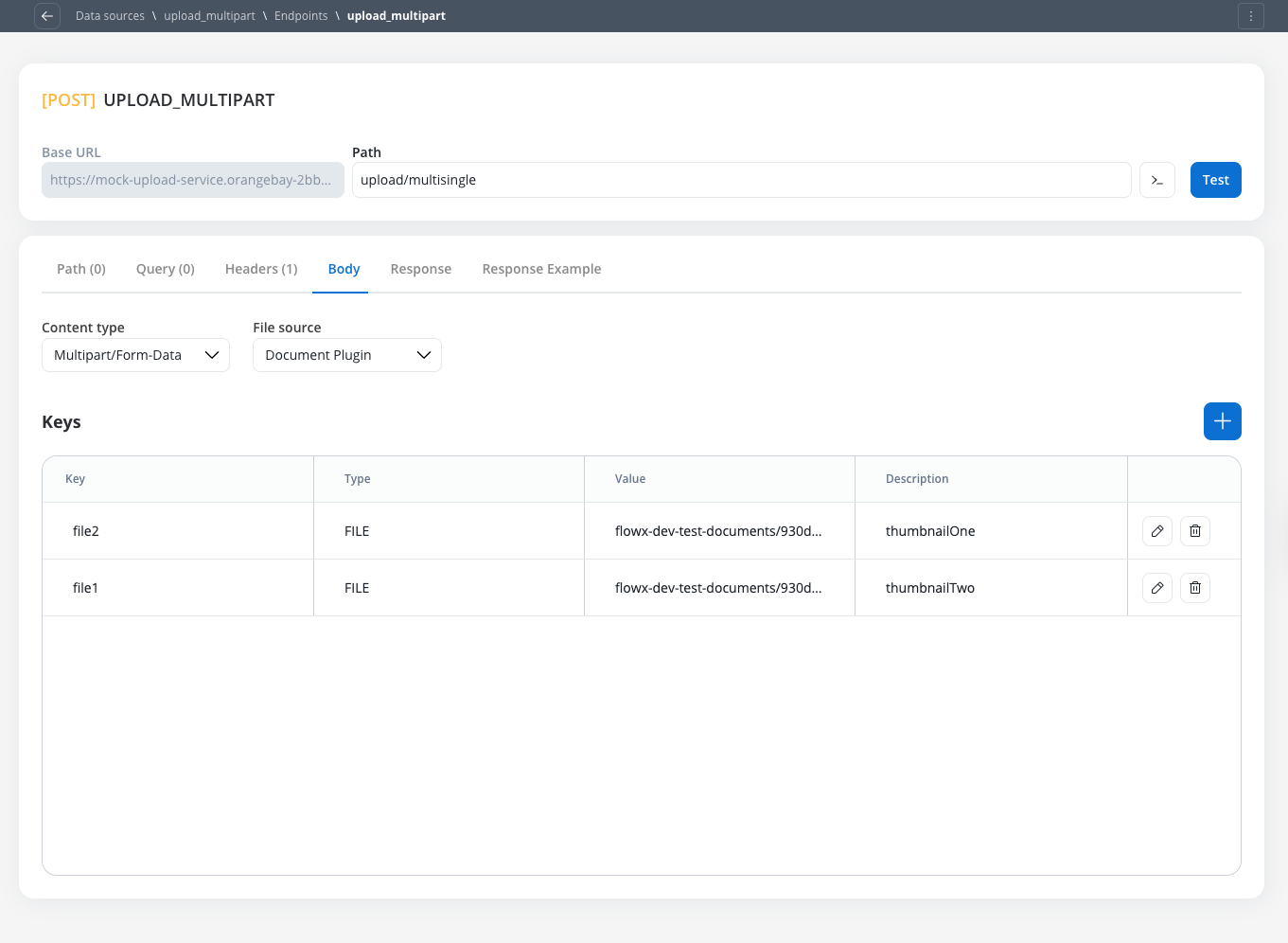
Text. The difference between content types is primarily in how data is packaged for transmission to the target server.Content Type: Single binary
Use this to send the raw file as the entire request body. This method sends only the file content without any additional form data or metadata.Document Plugin or S3 ProtocolContent Type: JSON
Runtime behavior & testing
Workflow node configuration
All configured file settings (for example,File Path, Folder, Process Instance ID) are exposed as parameters on the corresponding workflow nodes, allowing them to be set dynamically using process variables at runtime.
Response payload & logging
filePath to the stored file, not the raw Base64 string or binary content.filePath, not the raw file content.Error handling
If a node is configured to receive aSingle Binary file but the external system returns a JSON error (for example, file not found), the JSON error will be correctly passed through to the workflow for handling.
Testing guidelines
Body and Headers sections for better clarity.Example: sending files to an external system after uploading a file to the Document Plugin
Upload a file to the Document Plugin
- Configure a User Task node where you will upload the file to the Document Plugin.
- Configure an Upload File Action node to upload the file to the Document Plugin.
- Configure a Save Data Action node to save the file to the Document Plugin.
Workflows
A workflow defines a series of tasks and processes to automate system integrations. Within the Integration Designer, workflows can be configured using different components to ensure efficient data exchange and process orchestration.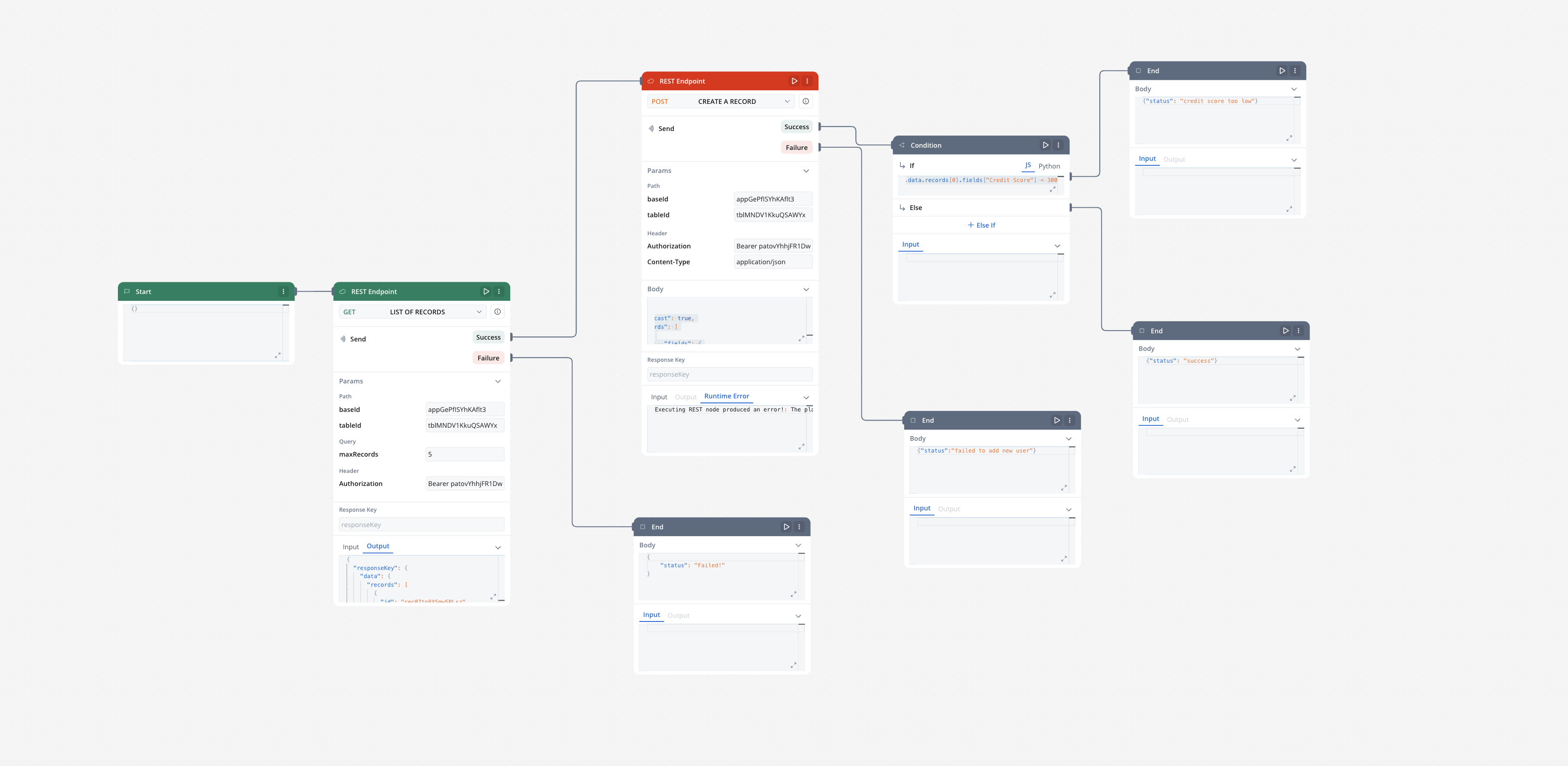
Creating a workflow
- Navigate to Workflow Designer:
- In FlowX.AI Designer to Projects -> Your application -> Integrations -> Workflows.
- Create a New Workflow, provide a name and description, and save it.
- Start to design your workflow by adding nodes to represent the steps of your workflow:
- Start Node: Defines where the workflow begins and also defines the input parameter for subsequent nodes.
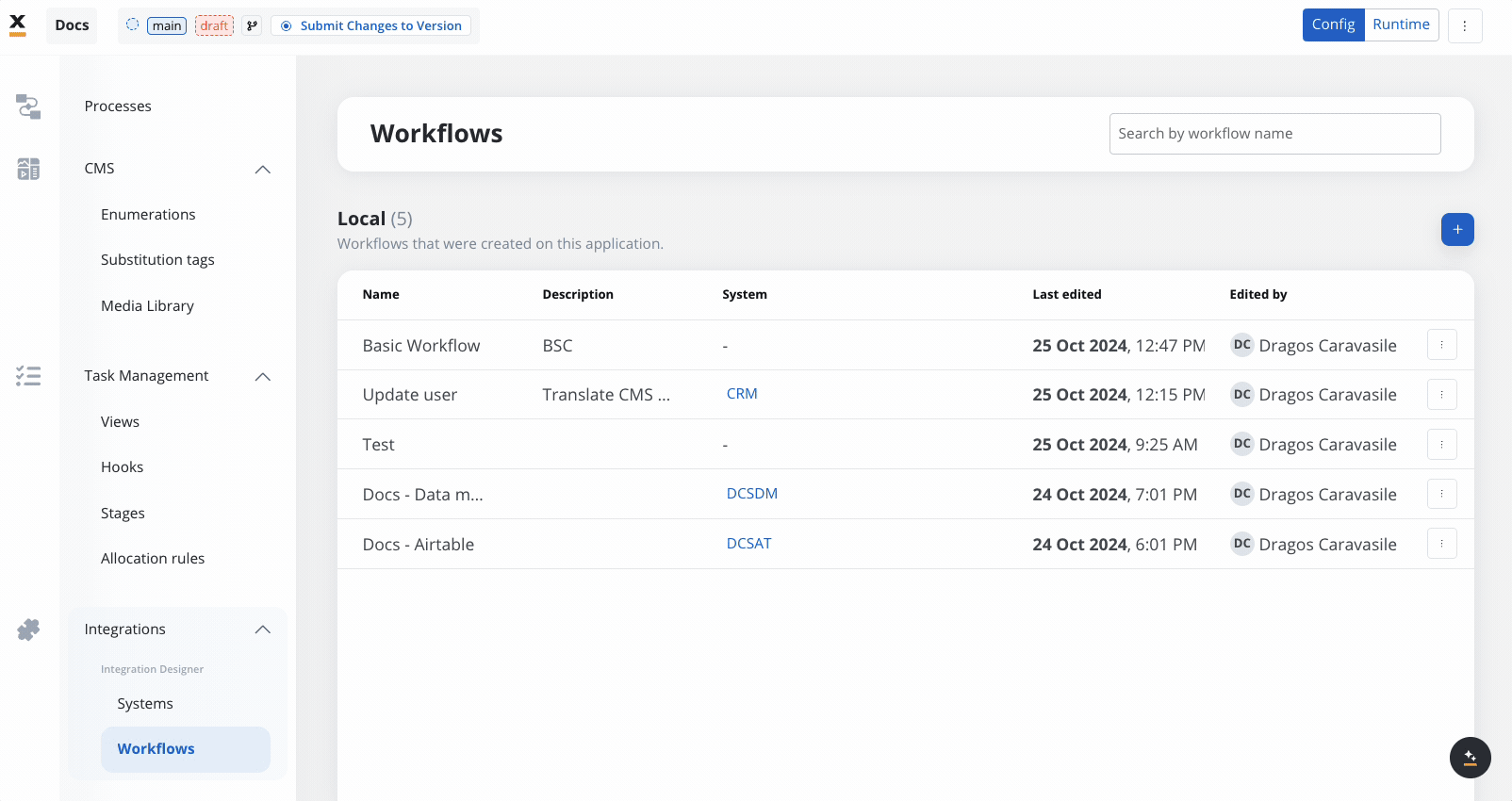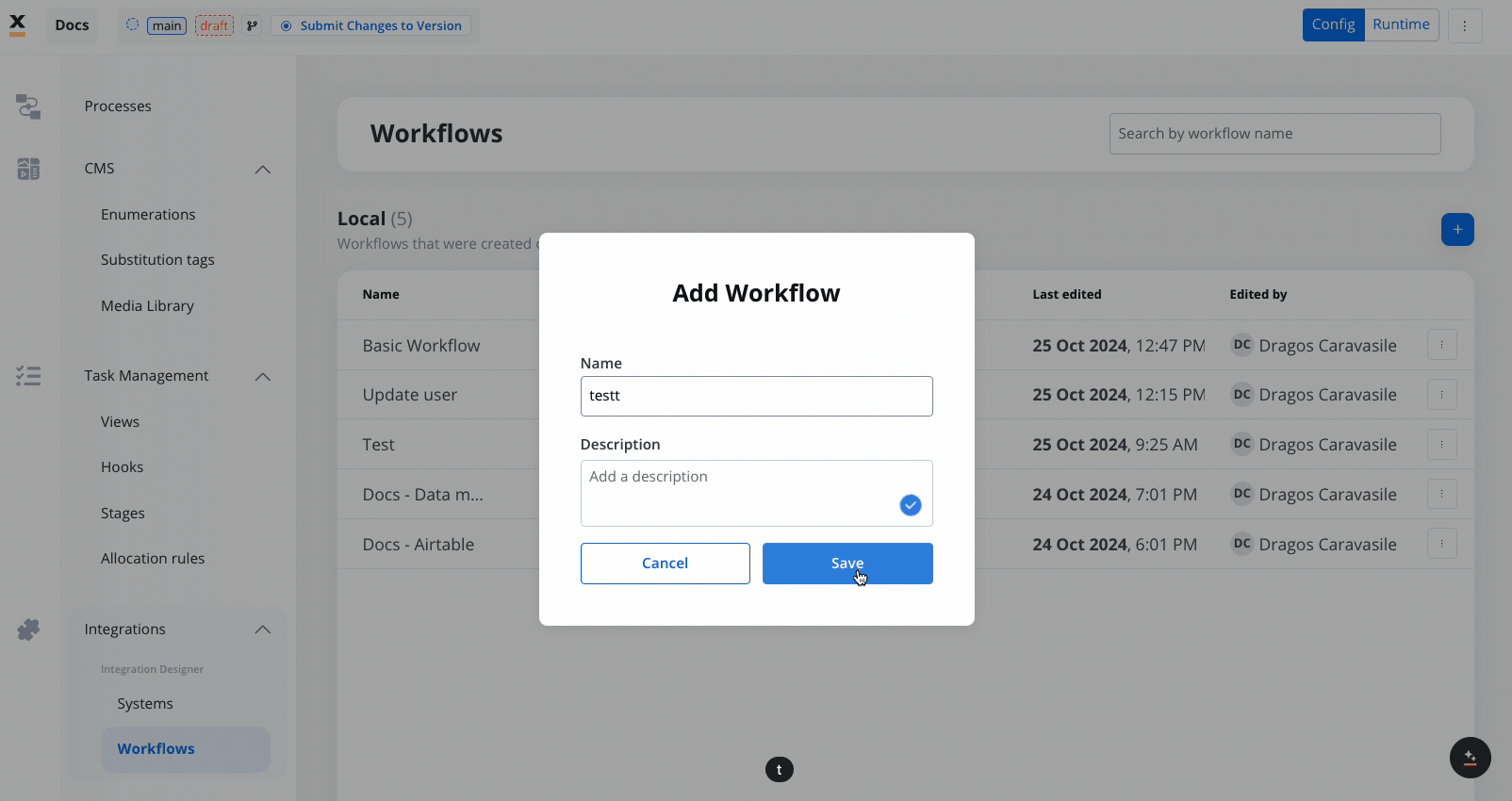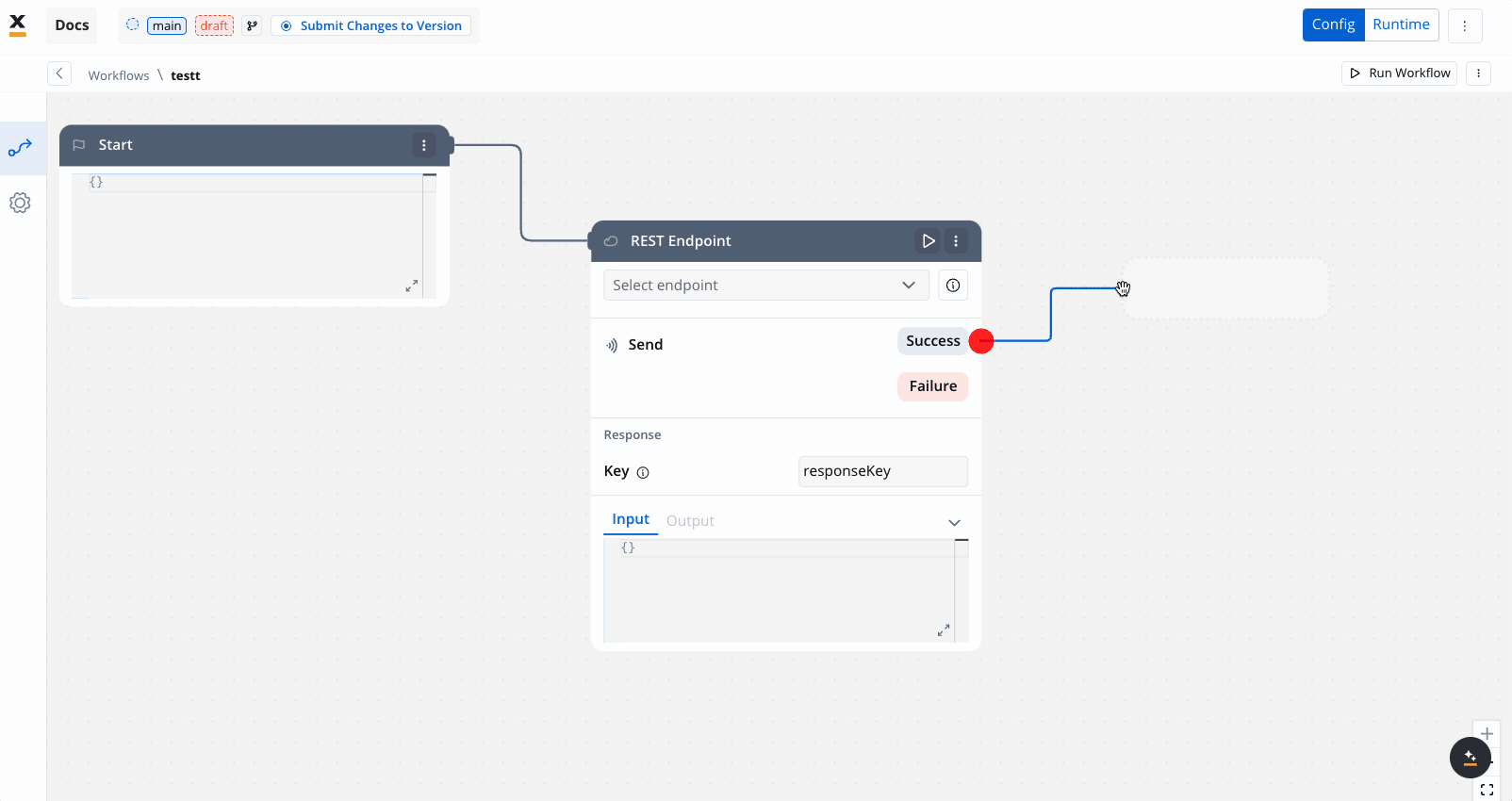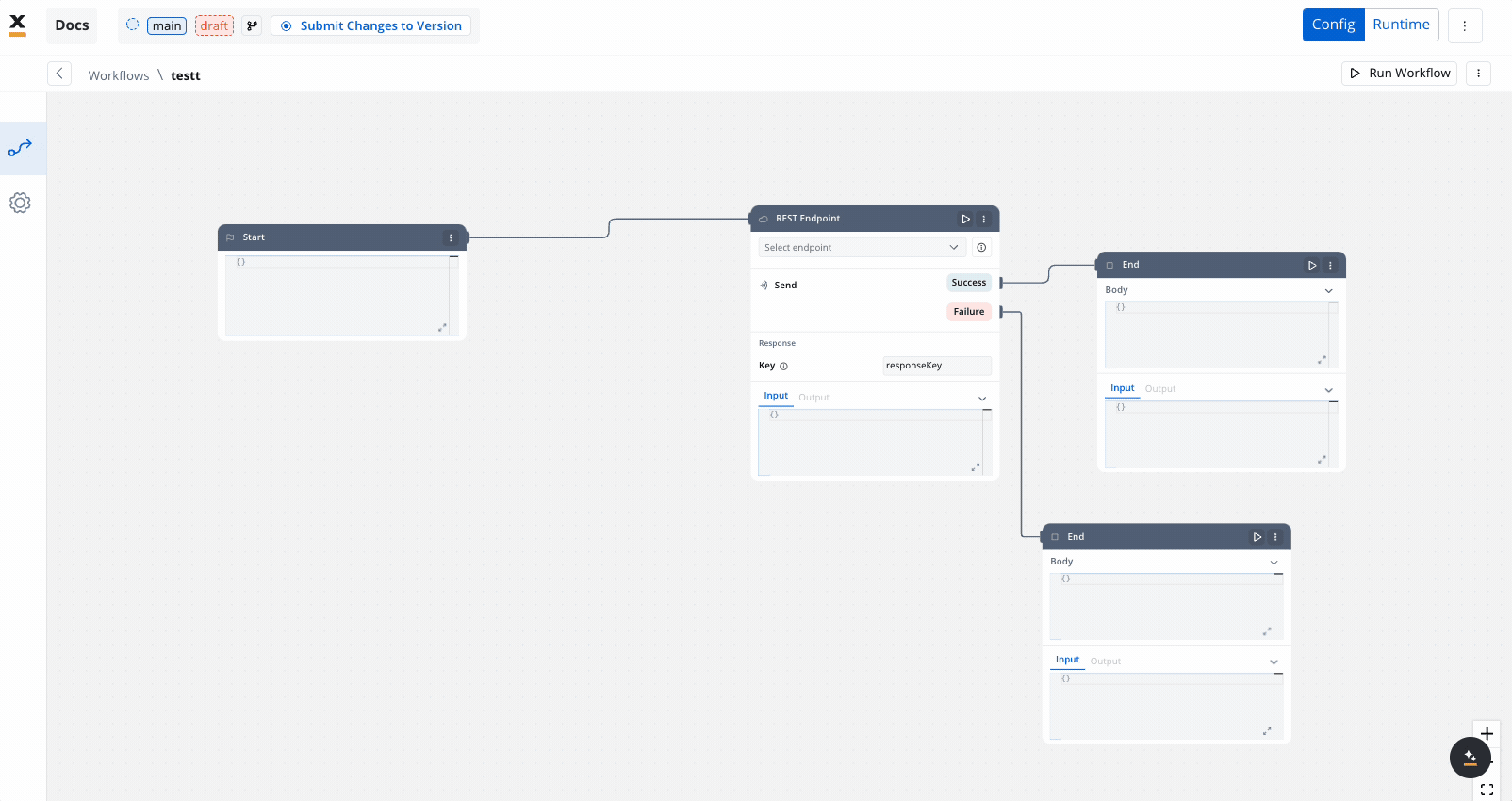
- REST endpoint nodes: Add REST API calls for fetching or sending data.
- FlowX Database nodes: Read and write data to FlowX Database collections.
- Custom Agent nodes: Enable AI agents to use MCP tools for intelligent task automation.
- Intent Classification nodes: Classify user messages using AI and route the workflow to the matching intent branch.
- Context Retrieval nodes: Perform RAG searches against Knowledge Bases to retrieve relevant chunks without calling an LLM.
- Parallel workflow execution: Execute multiple workflow branches concurrently to improve performance and reduce total execution time.
- Fork nodes (conditions): Add conditional logic for decision-making.
- Data mapping nodes (scripts): Write custom scripts in JavaScript or Python.
- Subworkflow nodes: Invoke other workflows as reusable components.
- Navigate in UI Flow nodes: Navigate users to specific UI Flow screens from conversational workflows, passing dynamic parameters.
- Web Page Extractor nodes: Crawl web pages, follow links up to a configurable depth, and extract content for use in workflows or Knowledge Bases.
- End Nodes: Capture output data as the completed workflow result, ensuring the process concludes with all required information.
- Update Knowledge Base: Update the Knowledge Base with the results of the workflow.
Workflow nodes overview
| Node Type | Purpose |
|---|---|
| Start Node | Defines workflow input and initializes data |
| REST Endpoint Node | Makes REST API calls to external systems |
| FlowX Database Node | Reads/writes data to the FlowX Database |
| Custom Agent Node | Enables AI agents to use MCP tools for intelligent automation |
| Intent Classification Node | Classifies user messages using AI and routes to matching intent branches |
| Context Retrieval Node | Retrieves relevant data from Knowledge Bases or memory using semantic, keyword, or hybrid search |
| AI Nodes | Process text, documents, images, and data using AI-powered capabilities |
| Condition (Fork) | Adds conditional logic and parallel branches |
| Script Node | Transforms or maps data using JavaScript or Python |
| Update Knowledge Base | Update the Knowledge Base with the results of the workflow |
| Subworkflow Node | Invokes another workflow as a modular, reusable subcomponent |
| Navigate in UI Flow | Navigates the user to a specific screen in a UI Flow from a conversational workflow |
| Web Page Extractor | Crawls web pages, follows links up to a configurable depth, and extracts content |
| End Node | Captures and outputs the final result of the workflow |
| Parallel Workflow Execution | Execute multiple workflow branches concurrently to improve performance and reduce total execution time |
Workflow data models
Key benefits
Automatic Input Management
Consistent Data Lineage
Type Safety
Better Integration
Quick start
Complete Workflow Data Models Guide
Start node
The Start node is the mandatory first node in any workflow. It defines the input data model and passes this data to subsequent nodes.REST endpoint node
Enables communication with external systems via REST API calls. Supports GET, POST, PUT, PATCH, and DELETE methods. Endpoints are selected from a dropdown, grouped by system.- Params: Configure path, query, and header parameters.
- Input/Output: Input is auto-populated from the previous node; output displays the API response.
FlowX database node
Allows you to read and write data to the FlowX Database within your workflow.FlowX Database Documentation
Context Retrieval node
- Source — choose between Knowledge Base or Memory (Memory is available only in conversational workflows)
- Knowledge Base — select a Knowledge Base to search (when source is Knowledge Base)
- User Query — the search query, supports process variable expressions (e.g.,
${userMessage}) - Search Type — Hybrid (default), Semantic, or Keywords
- Max Number of Chunks — how many chunks to return (1-10, default: 5)
- Min Relevance Score — minimum relevance threshold (0-100%, default: 70%)
- Metadata Filters — filter chunks by metadata properties using the query builder: typed operators per key type and AND/OR grouping
- Use advance metadata filters — toggle to enable expression-based filtering for complex logic
- Use Re-rank — toggle to re-rank retrieved chunks before returning
Using Knowledge Base in Workflows
Custom Agent node
Enables AI agents to perform intelligent, autonomous tasks using Model Context Protocol (MCP) tools within your workflow. Custom Agent nodes apply ReAct (Reasoning and Acting) to decide which tools to use and execute multi-step operations. Key capabilities:- Access external systems through MCP servers
- Execute complex, multi-step operations autonomously
- Make intelligent decisions based on available tools
- Return structured responses for downstream processing
- Customer support automation with CRM integration
- Data analysis across multiple systems
- Dynamic integration orchestration
- Autonomous problem-solving workflows
Custom Agent Node Documentation
Intent Classification node
- Define up to 10 intents as plain-text descriptions
- Automatic “If No Intent Matches” fallback branch
- Optional conversation memory for context-aware classification
- Optional rationale output explaining the classification decision
- Chatbot message routing
- Email triage and classification
- Customer support ticket categorization
Intent Classification Documentation
Context Retrieval node
Performs a RAG (Retrieval-Augmented Generation) search against a Knowledge Base and returns relevant chunks — without calling an LLM. Use this node when you need to retrieve information from a Knowledge Base and pass it to downstream nodes for further processing. Key capabilities:- Query Knowledge Bases using semantic, keyword, or hybrid search
- Configure relevance thresholds and result limits
- Apply property-based filters to narrow results
- Optional re-ranking for improved result quality
- Returns structured chunk data (content, metadata, relevance score, store)
- Feeding context into a downstream Custom Agent or Text Generation node
- Building multi-step RAG pipelines with custom processing between retrieval and generation
- Retrieving relevant documentation chunks for further analysis
Context Retrieval Documentation
AI Nodes
AI nodes enable intelligent processing of text, documents, images, and data directly within your Integration Designer workflows.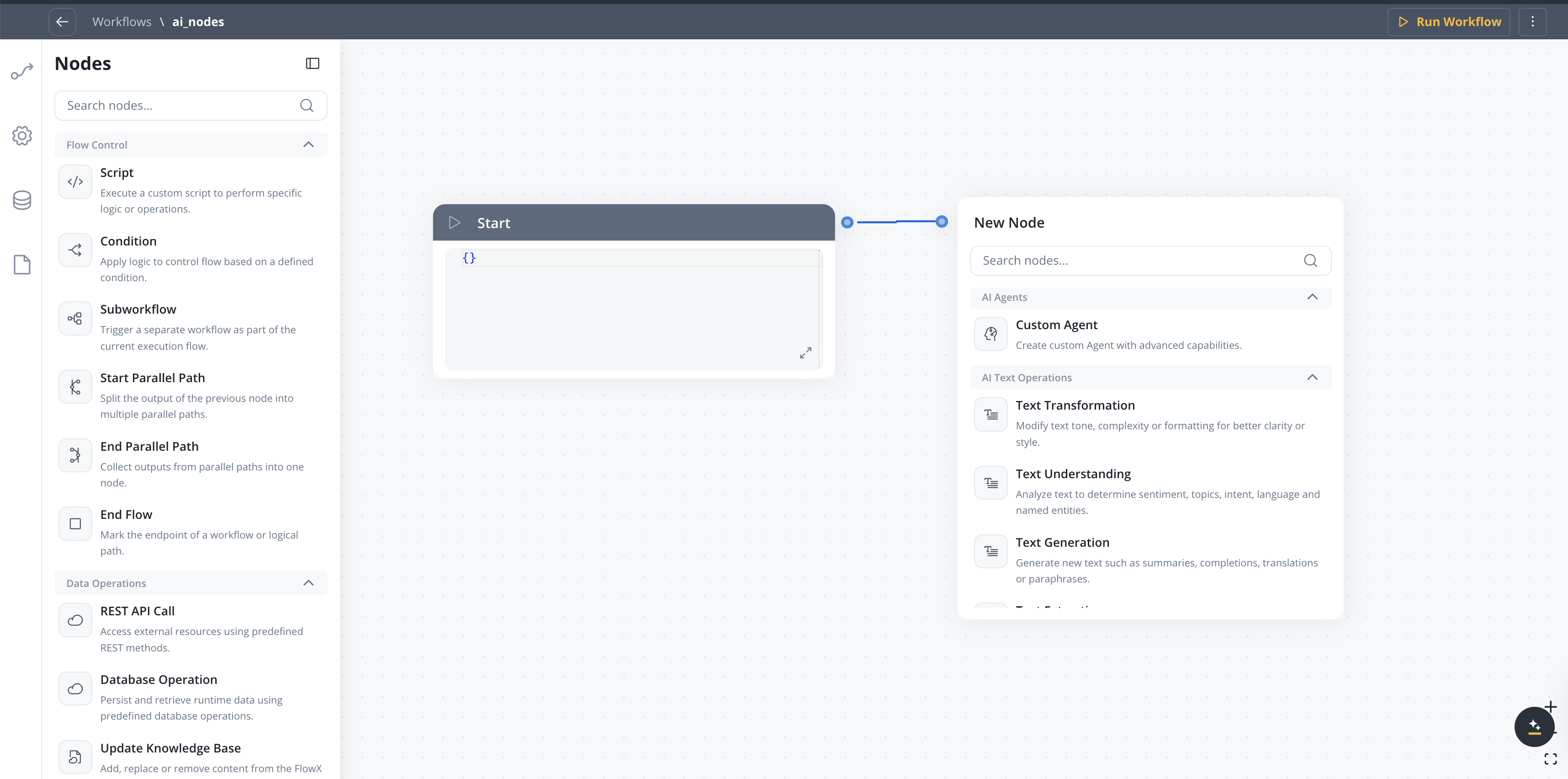
AI Text Operations
| Node | Description |
|---|---|
| Text Transformation | Modify text tone, complexity or formatting for better clarity or style |
| Text Understanding | Analyze text to determine sentiment, topics, intent, language and named entities |
| Text Generation | Generate new text such as summaries, completions, translations or paraphrases |
| Text Extraction | Extract structured information, keywords or metadata from text |
AI Document Operations
| Node | Description |
|---|---|
| Document Generation | Automatically build reports or complete templates based on given inputs |
| Document Extraction | Identify and extract structured data, entities or metadata from documents |
| Document Understanding | Analyze documents to extract meaning, topics, sentiment, or important information |
| Extract Data from File | Extract text and data from documents and images using LLM, OCR, or text parsing |
AI Image Operations
| Node | Description |
|---|---|
| Image Description | Generate captions or extract detailed information from visual content |
| Image Analysis | Recognize objects, emotions and scenes in images for contextual understanding |
AI Data Operations
| Node | Description |
|---|---|
| Data Enrichment | Add annotations, context or relationships to enhance raw data value |
| Data Generation | Produce synthetic or structured data using templates and logic-based rules |
| Data Transformation | Clean, normalize, aggregate, or restructure datasets into usable formats |
AI Node Types
Personal Information Guard
| Field | Description |
|---|---|
enabled | Turn the guard on for the node. |
sensitivityPreset | One of STRICT, BALANCED, RELAXED, CUSTOM. Maps to a server-side detection threshold; CUSTOM exposes the customSensitivity slider (0.00–1.00). |
customSensitivity | Threshold value used when sensitivityPreset = CUSTOM. |
scanDirections | Set of INPUT and/or OUTPUT. Both can be enabled. Empty sets are rejected. |
entityKeys | Entity types to detect (e.g., EMAIL_ADDRESS, PHONE_NUMBER, IBAN_CODE). The Designer modal groups them under three scopes: Universal, Regional EN, and Regional RO. The catalog is served from GET /integration/api/workflows/personal-information-guard/entities. |
- Input scan runs before the AI request is built, so placeholder substitution and the user-message extraction both see redacted data. The
systemPromptis scanned alongside inputs because operation-prompt templates may carry PII from earlier nodes. - Source-file scan runs for document and image AI nodes. The Data Privacy service uploads the redacted artifact back to the same storage as the source (so
filePathForRequestis swapped without changing the data source binding). - Output scan runs after the LLM completes, on a bounded-elastic scheduler so the Data Privacy WebClient call does not pin the reactor-netty event loop.
- System-prompt appender — for Custom Agent nodes, the runner appends a non-editable segment teaching the LLM how to handle
<PII type=.../>placeholders. The appender runs after the prompt scan so its literal tags are not mistaken for PII. - Fail-closed — any error from the Data Privacy service stops execution. The error surfaces on the node run log; redacted artifacts are not produced on failure.
personalInformationGuard block on the node response (AiNodeResponseDetailsDTO):
| Field | Description |
|---|---|
status | SUCCESS, SKIPPED, or ERROR. |
detections | Per-entity counts of substitutions performed. |
errorMessage | Populated when status = ERROR. |
sourceType | INPUT, SYSTEM_PROMPT, OUTPUT, or FILE. |
originalStoragePath, redactedStoragePath | Set for FILE scans; both point at the data source bound to the node. |
FLOWX_DATAPRIVACY_BASEURL and FLOWX_DATAPRIVACY_TIMEOUTSECONDS in the Integration Designer setup guide.
Condition (Fork) node
Evaluates logical conditions (JavaScript or Python) to direct workflow execution along different branches.- If/Else: Routes based on condition evaluation.
- Parallel Processing: Supports multiple branches for concurrent execution.
Available bindings
Condition expressions have access to the following data bindings:| Binding | Description |
|---|---|
input | Workflow input data from the previous node |
additionalData.securityDetails | Current user’s identity (username, identifier, details including roles, groups, and attributes from 5.7.0 onward) |
additionalData.applicationConfiguration | Configuration parameters from the app build |
Condition examples
- JavaScript
- Python
Parallel workflow execution
Parallel Workflows
Key concepts
Start Parallel Node
End Parallel Node
Path Visualization
Runtime Monitoring
How to use parallel workflows
Design Parallel Paths
Configure Branch Logic
Merge Paths
Use cases
Multiple API Calls
Data Enrichment
Notification Broadcasting
Document Processing
Runtime behavior
Data at fork (Start Parallel)
Data at fork (Start Parallel)
Data merge at join (End Parallel)
Data merge at join (End Parallel)
- Each branch’s modified keys are merged into the parent data
- If two branches modify different keys, both changes are preserved
- If two branches modify the same key, the last branch to finish overwrites the earlier value
- For nested objects, the merge is recursive — only conflicting leaf values are overwritten
- For arrays, no element-level merge occurs — the entire array is replaced by the last branch’s version
Path Timing
Path Timing
- Path Time: Sum of all node execution times within that branch
- End Parallel Time: Node processing time + maximum time across all parallel paths
- Example: If Branch A takes 2s and Branch B takes 5s, the End Parallel node completes after 5s (plus its own processing time)
Console Logging
Console Logging
- Start Parallel Node: Displays Input tab showing data split across branches
- End Parallel Node: Displays Output tab showing merged results from all branches
- Path Grouping: Nodes within each parallel path are grouped for easy monitoring
Error Handling
Error Handling
- If any branch fails, the workflow handles it according to standard error handling rules
- The End Parallel node waits for all non-failed branches to complete before merging
- If branches do not converge to the same End Parallel node, the workflow fails with a
Missing end parallel gatewayerror
Limitations and considerations
- Last-write-wins merge: When multiple branches modify the same data key, the final value depends on which branch completes last. This is non-deterministic if branch durations vary. To preserve data from all branches, write to different keys and merge manually in a Script node after the End Parallel
- Array handling: Arrays are not merged element-by-element. The entire array is replaced by the last branch’s version. You cannot process individual array elements in separate branches (e.g., first element in branch 1, second element in branch 2)
- Branch closure: All branches from a Start Parallel must converge to the same End Parallel node. The End Parallel node can have only one outgoing sequence
- Nested parallel paths: Start Parallel nodes can be nested inside other parallel branches for multi-level concurrency
- No cross-branch dependencies: Branches execute concurrently on independent data copies. One branch cannot read data written by another branch during execution
Script node
Executes custom JavaScript or Python code to transform, map, or enrich data between nodes.Subworkflow node
The Subworkflow node allows you to modularize complex workflows by invoking other workflows as reusable subcomponents. This approach simplifies process design, promotes reuse, and simplifies maintenance.Add a Subworkflow Node
Configure the Subworkflow Node
- Workflow Selection: Pick the workflow to invoke.
- Open: Edit the subworkflow in a new tab.
- Preview: View the workflow canvas in a popup.
- Response Key: Set a key (e.g.,
response_key) for output. - Input: Provide input in JSON format.
- Output: Output is read-only JSON after execution.
Execution logic and error handling
- Parent workflow waits for subworkflow completion before proceeding.
- If the subworkflow fails, the parent workflow halts at this node.
- Subworkflow output is available to downstream nodes via the response key.
- Logs include workflow name, instance ID, and node statuses for both parent and subworkflow.
Console logging, navigation, and read-only mode
- Console shows input/output, workflow name, and instance ID for each subworkflow run.
- Open subworkflow in a new tab for debugging from the console.
- Breadcrumbs enable navigation between parent and subworkflow details.
- In committed/upper environments, subworkflow configuration is read-only and node runs are disabled (preview/open only).
Use case: CRM Data Retrieval with subworkflows
Suppose you need to retrieve CRM details in a subworkflow and use the output for further actions in the parent workflow.Create the Subworkflow
Add a Subworkflow Node in the Parent Workflow
Use Subworkflow Output in Parent Workflow
responseKey.End node
The End node signifies the termination of a workflow’s execution. It collects the final output and completes the workflow process.- Receives input in JSON format from the previous node.
- Output represents the final data model of the workflow.
- Multiple End nodes are allowed for different execution paths.
Running and stopping workflows
- Run Workflow: Click Run Workflow in the workflow editor toolbar to start a new workflow instance. You can provide start data in JSON format before running.
- Stop Run: While a workflow instance is running, the button changes to Stop Run. Click it to cancel the instance. All in-progress and scheduled nodes are marked as cancelled.
| Status | Description |
|---|---|
| Started | The workflow instance is currently running |
| Finished | The workflow instance completed successfully |
| Failed | The workflow instance encountered an error |
| Cancelled | The workflow instance was manually stopped by the user |
Integration with external systems
This example demonstrates how to integrate FlowX with an external system, in this example, using Airtable, to manage and update user credit status data. It walks through the setup of a data source, defining API endpoints, creating workflows, and linking them to BPMN processes in FlowX Designer.- Create your own base and table in Airtable. For more information, see the Airtable base creation guide.
- Review the Airtable Web API documentation to get familiarized with the Airtable API.
Integration in FlowX.AI
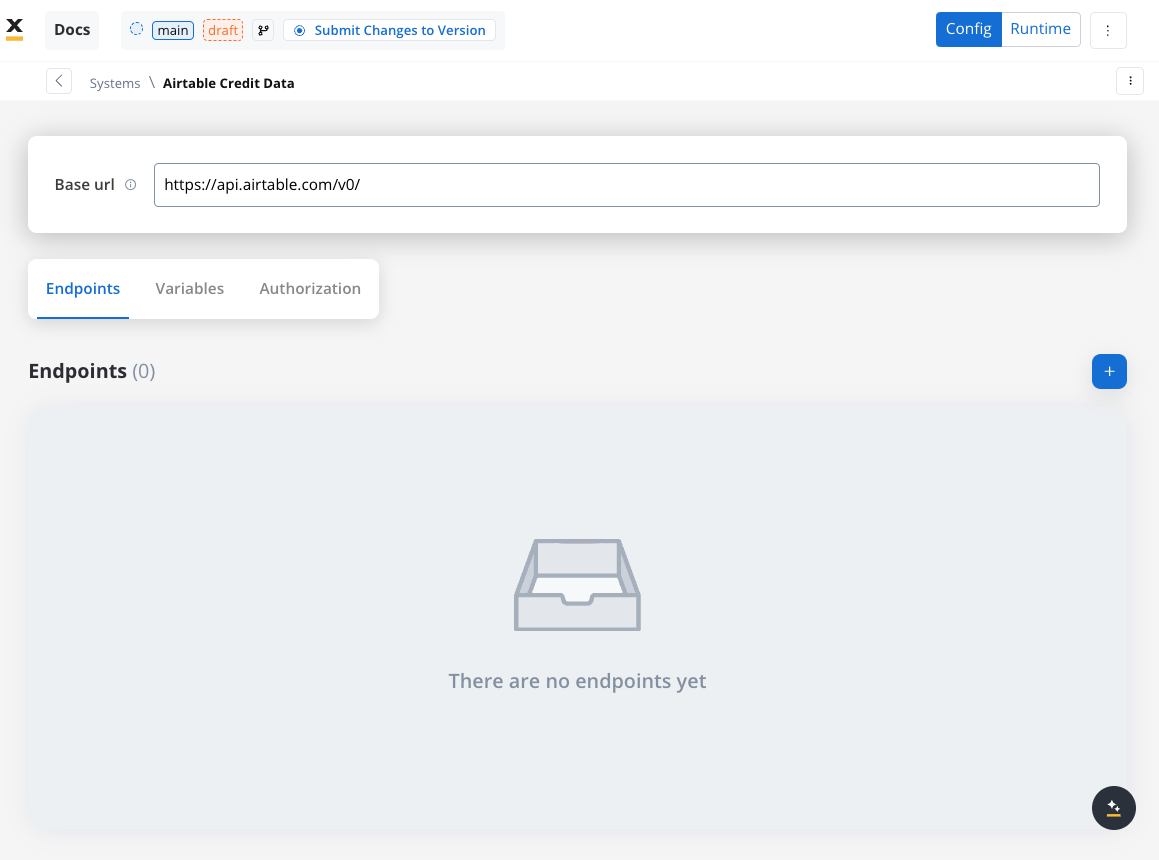
Define a Data Source
- Name: Airtable Credit Data
- Base URL:
https://api.airtable.com/v0/
Define Endpoints
- Get Records Endpoint:
- Method: GET
- Path:
/${baseId}/${tableId} - Path Parameters: Add the values for the baseId and for the tableId so they will be available in the path.
- Header Parameters: Authorization Bearer token
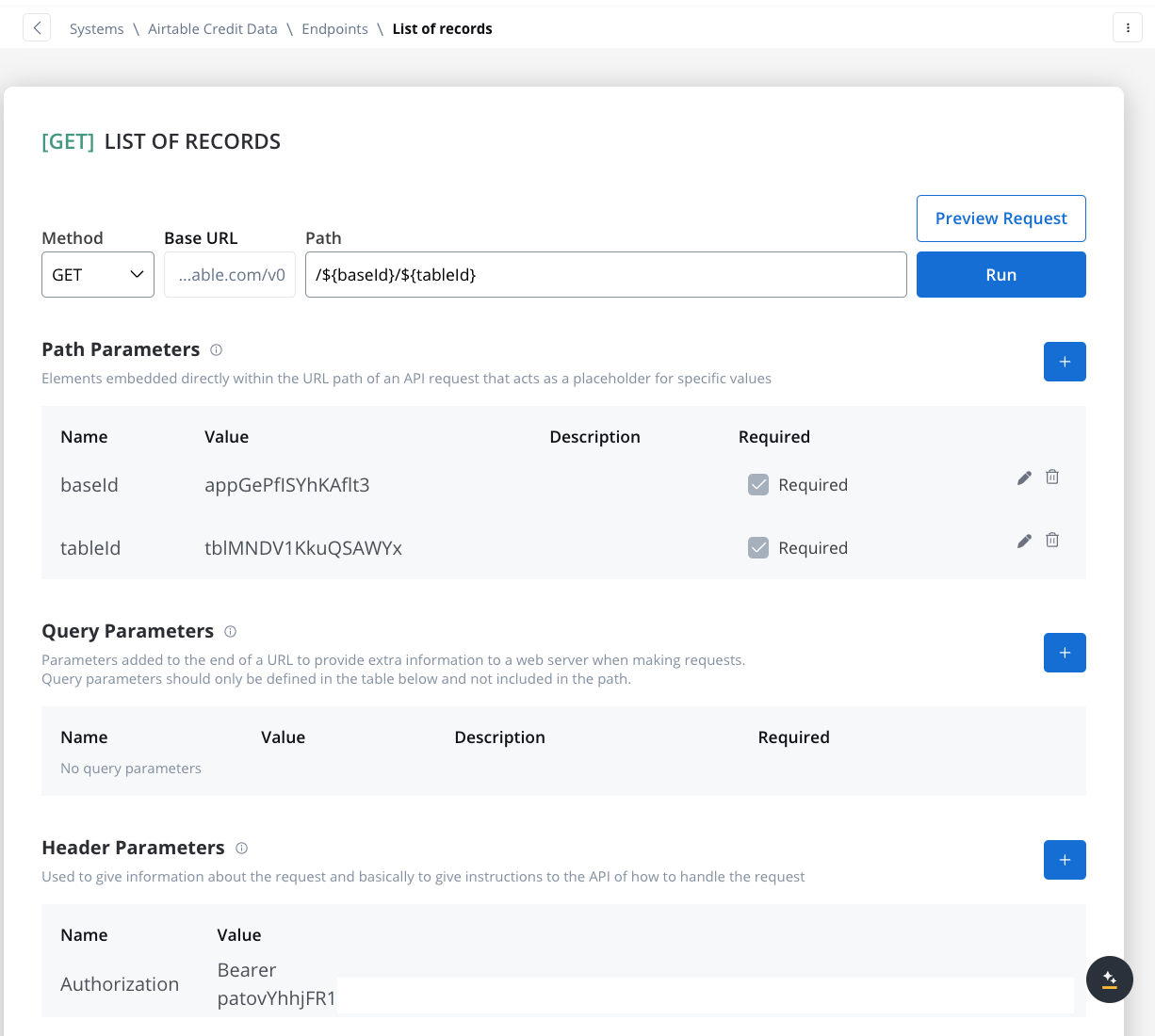
- Create Records Endpoint:
- Method: POST
- Path:
/${baseId}/${tableId} - Path Parameters: Add the values for the baseId and for the tableId so they will be available in the path.
- Header Parameters:
Content-Type: application/json- Authorization Bearer token
- Body: JSON format containing the fields for the new record. Example:
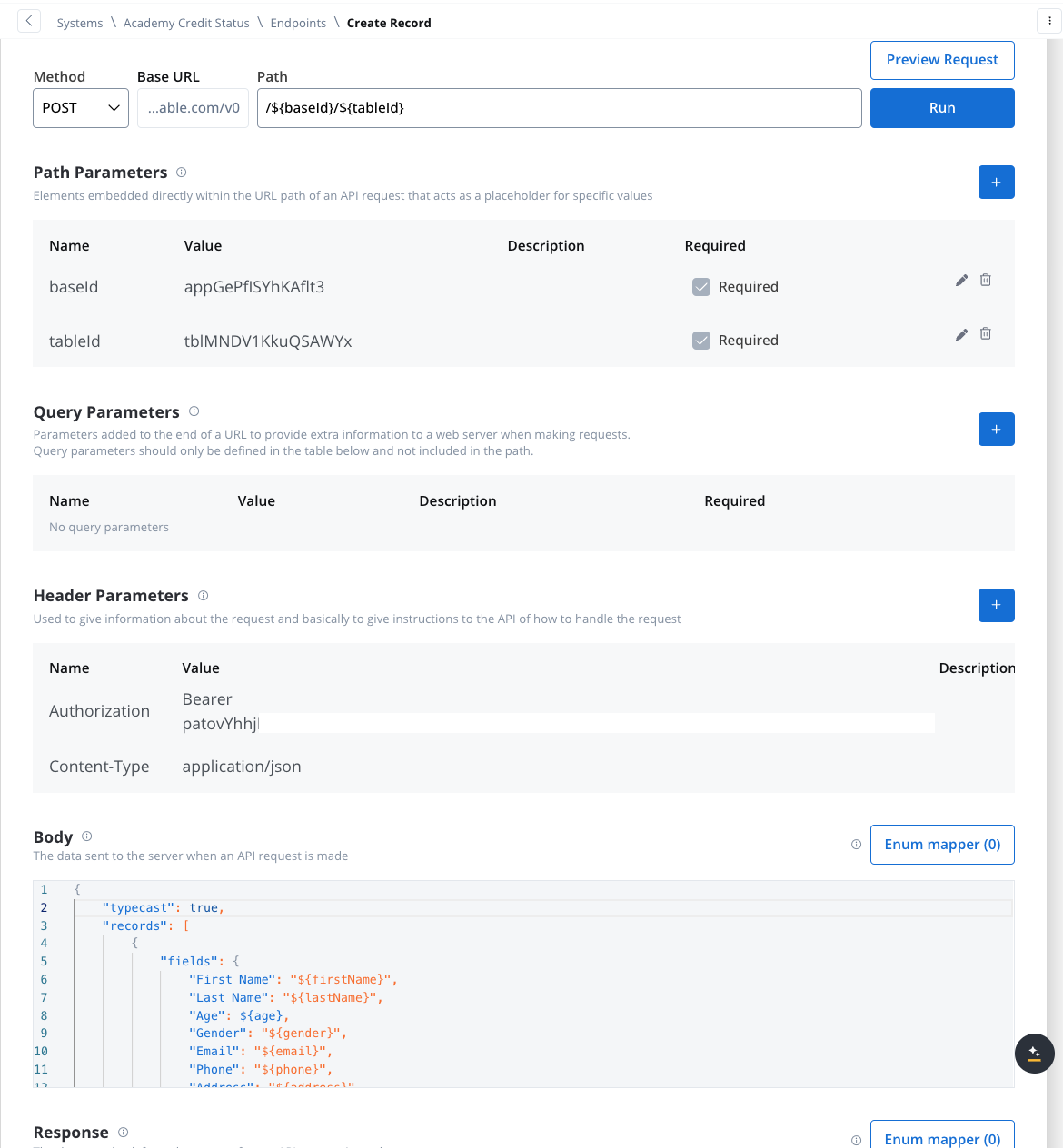
Design the Workflow
-
Open the Workflow Designer and create a new workflow.
- Provide a name and description.
-
Configure Workflow Nodes:
- Start Node: Initialize the workflow.
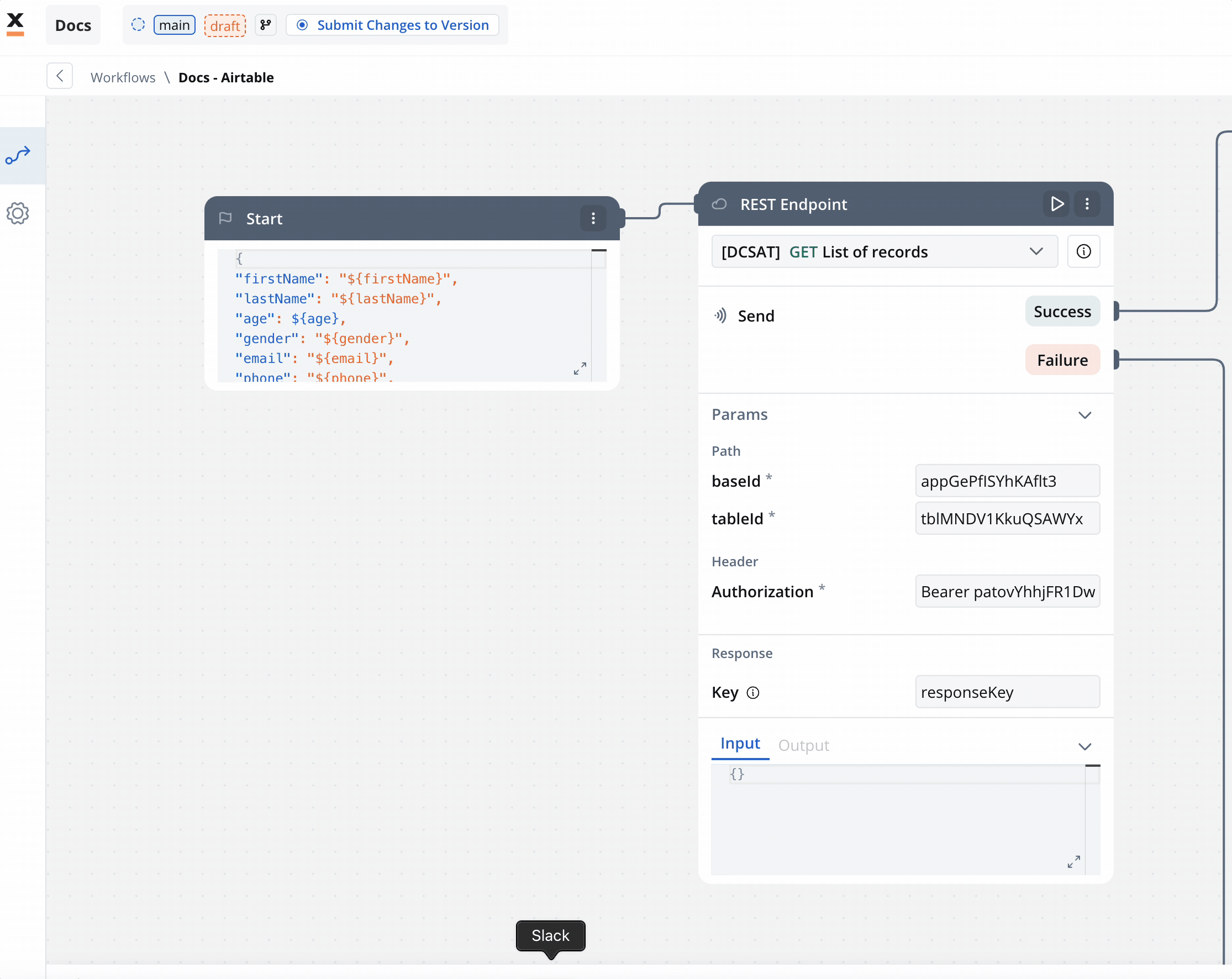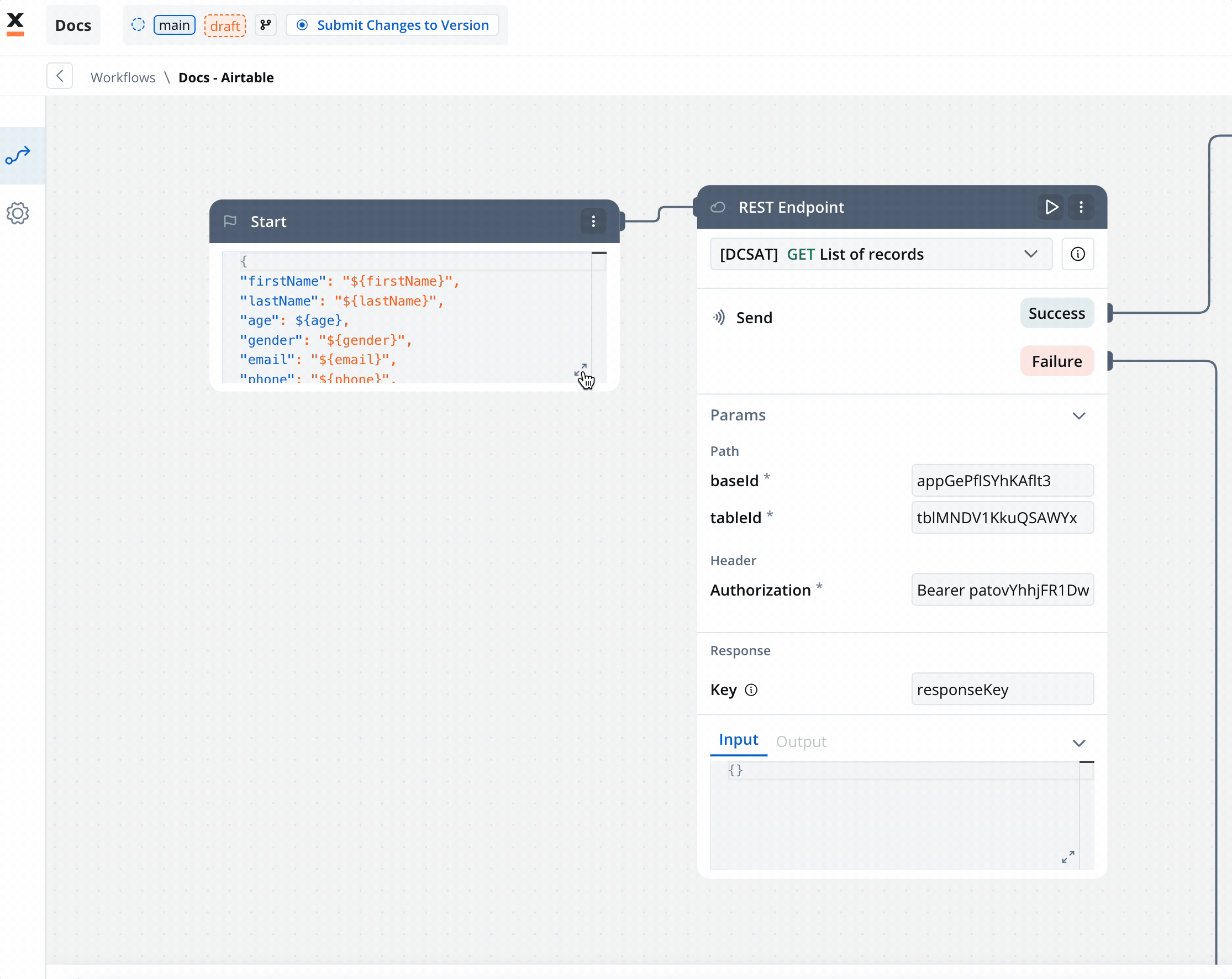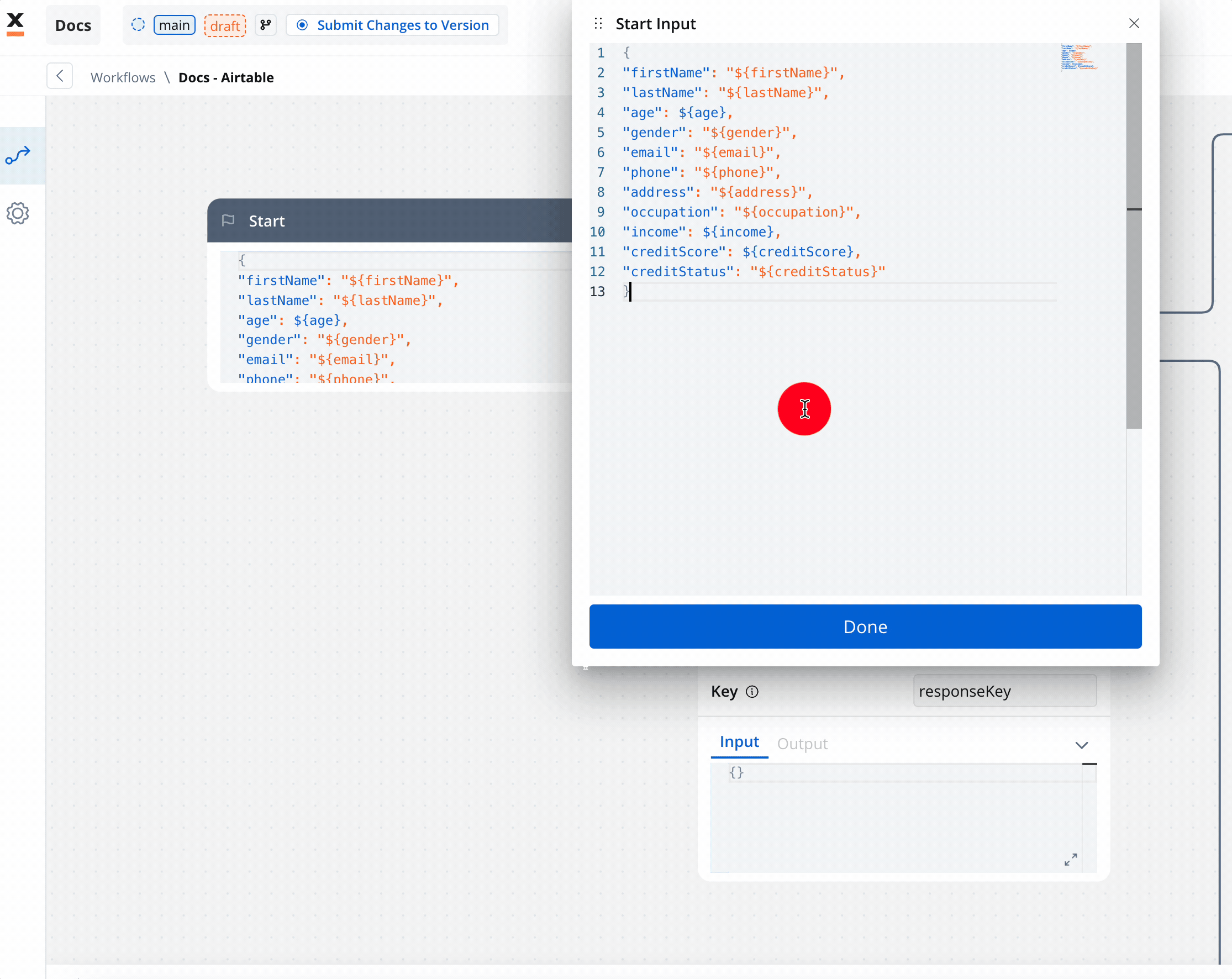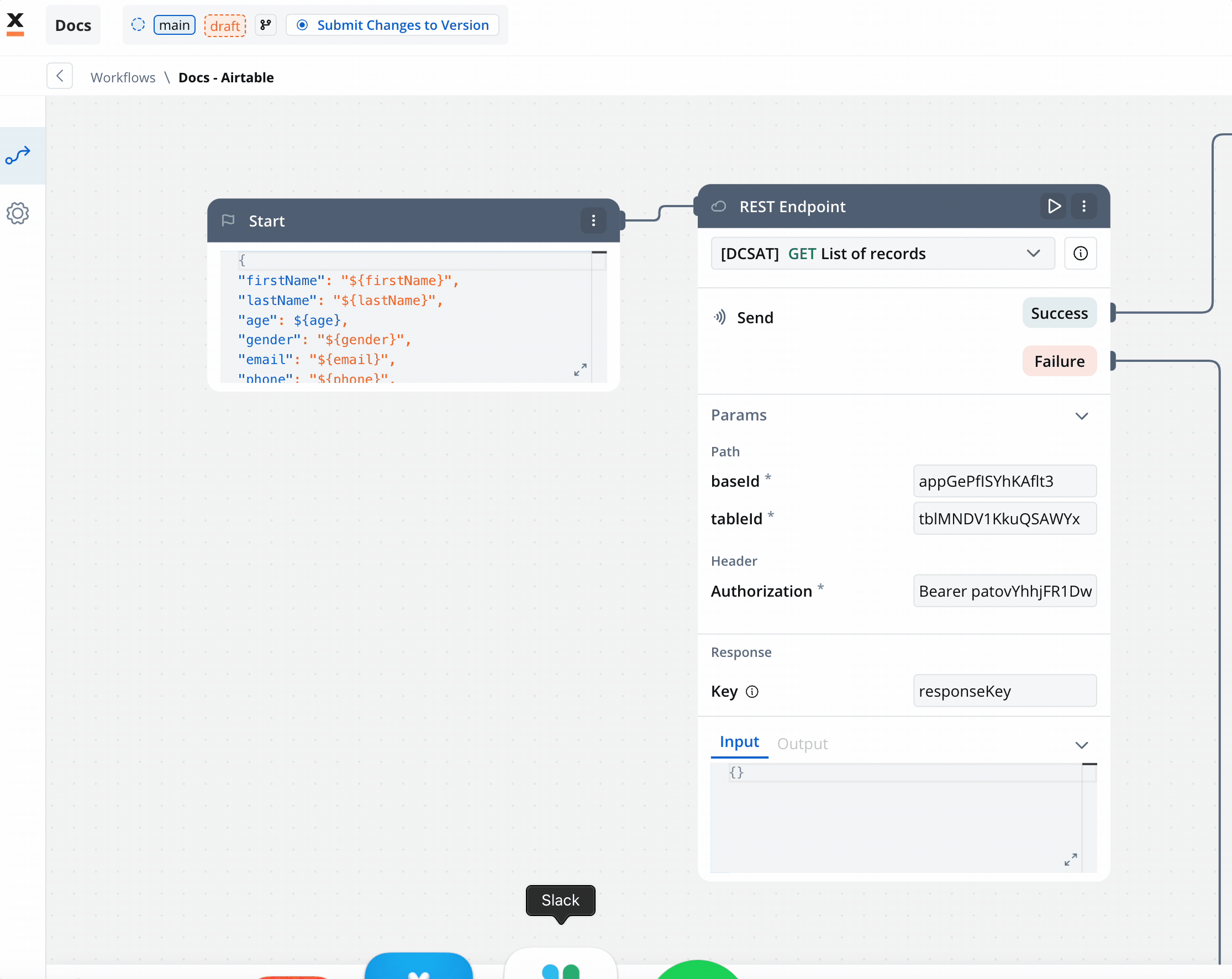
- REST Node: Set up API calls:
- GET Endpoint for fetching records from Airtable.
- POST Endpoint for creating new records.
- Condition Node: Add logic to handle credit scores (e.g., triggering a warning if the credit score is below 300).
- Script Node: Include custom scripts if needed for processing data (not used in this example).
- End Node: Define the end of the workflow with success or failure outcomes.
Link the Workflow to a Process
- Integrate the workflow into a BPMN process:
- Open the process diagram and include a User Task and a Receive Message Task.
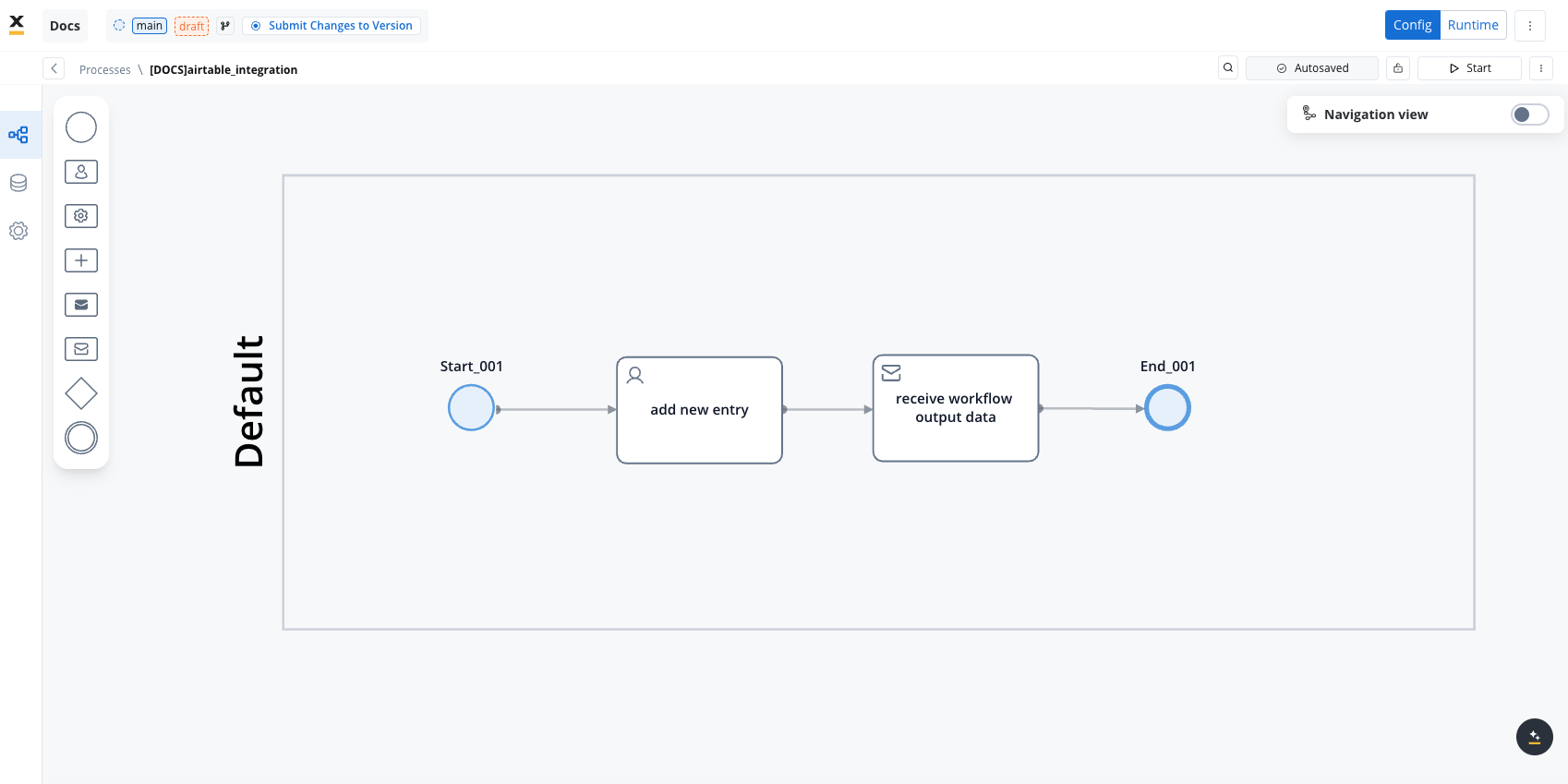
- Map Data in the UI Designer:
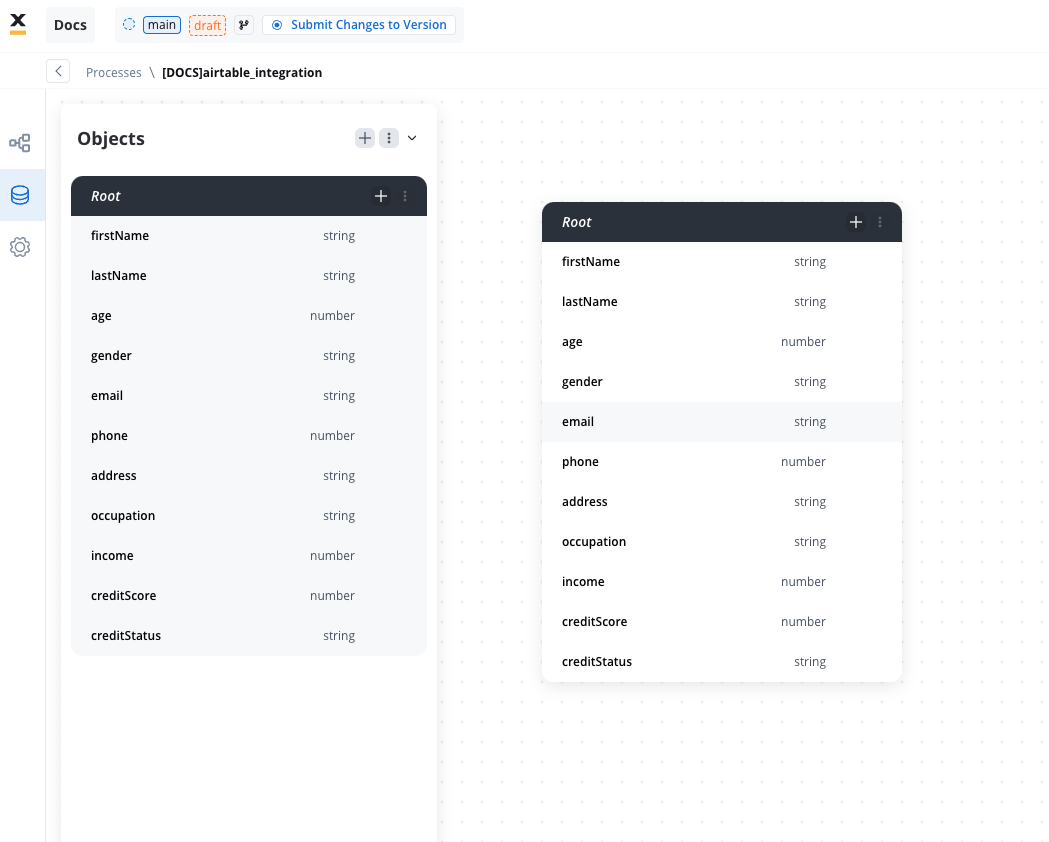
- Create the data model
- Link data attributes from the data model to form fields, ensuring the user input aligns with the expected parameters.
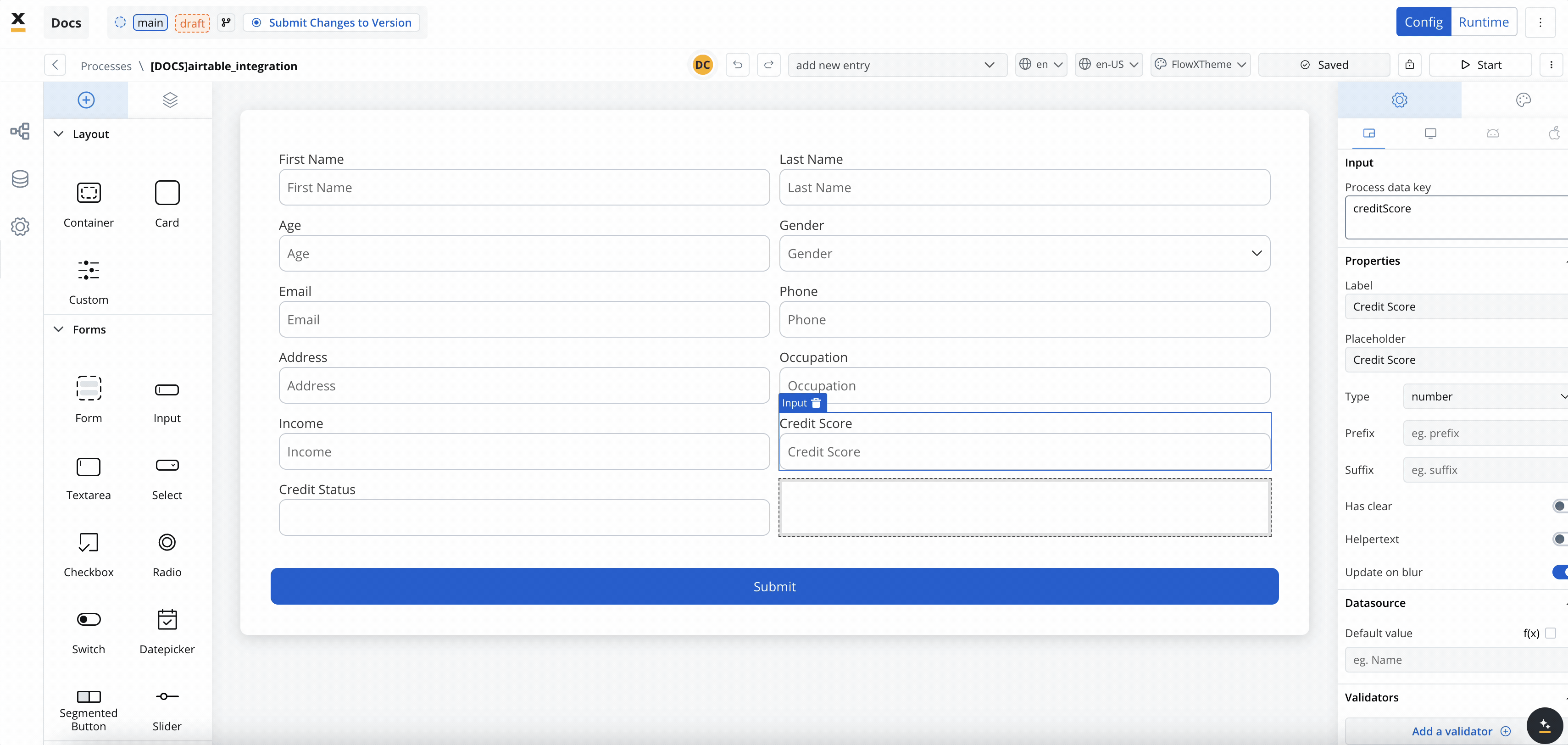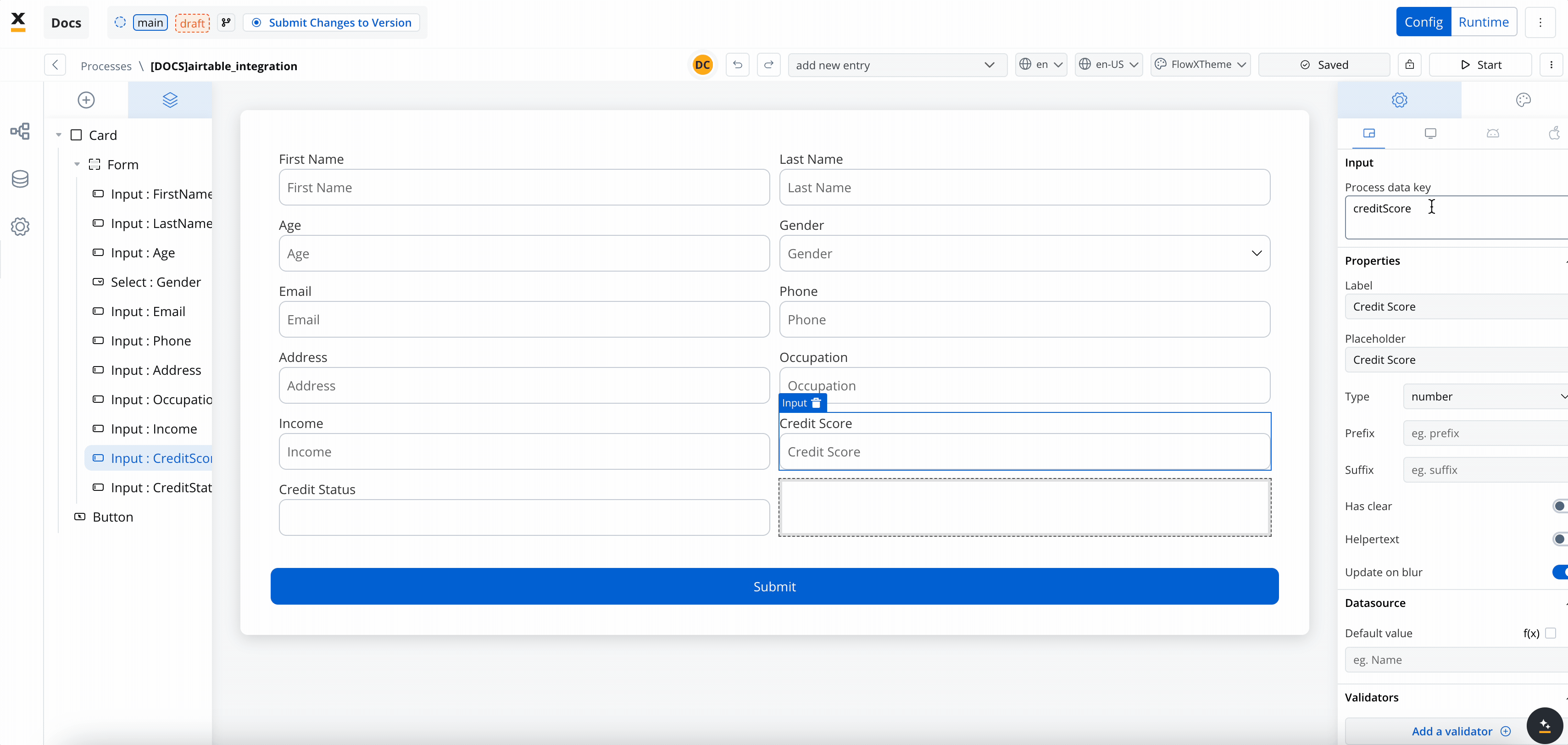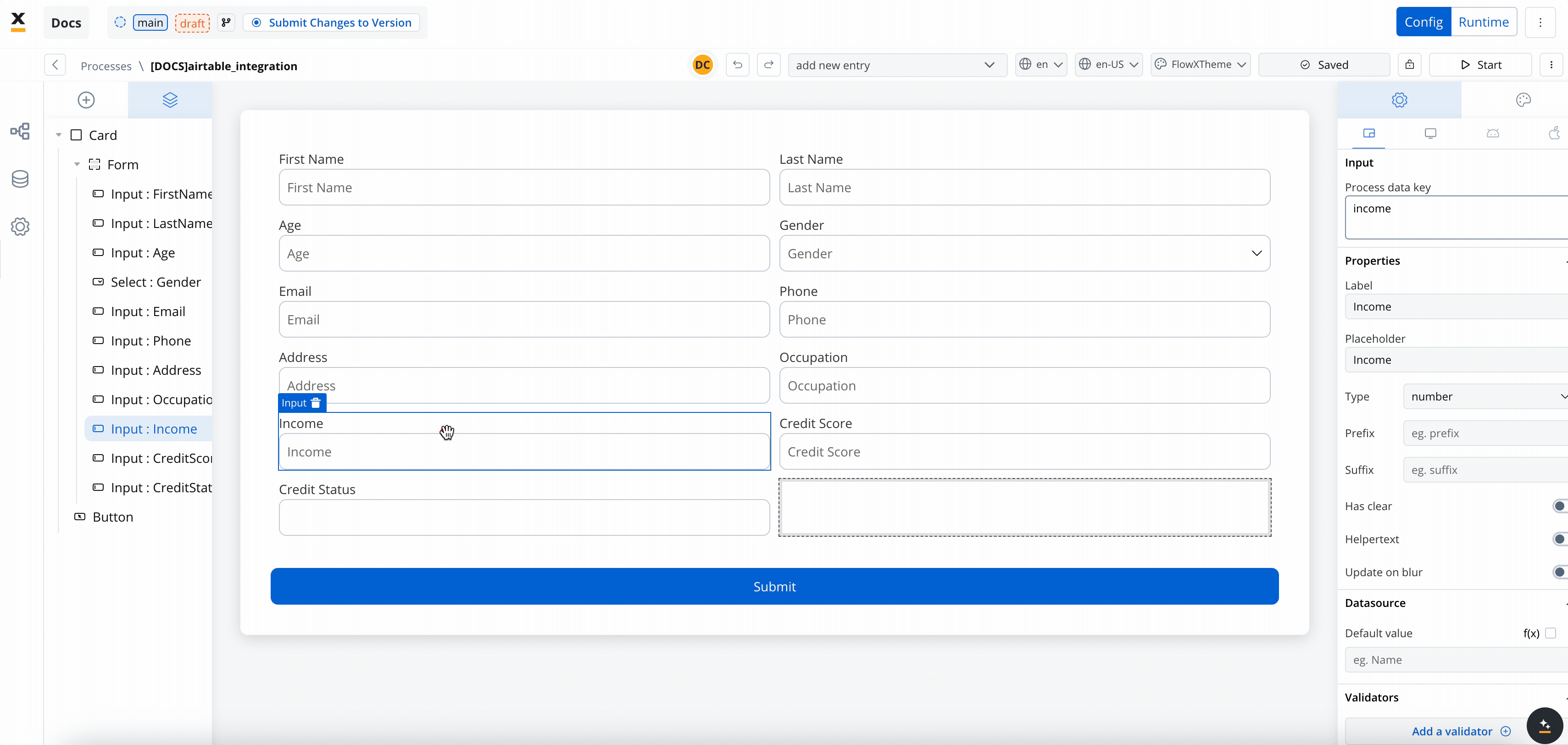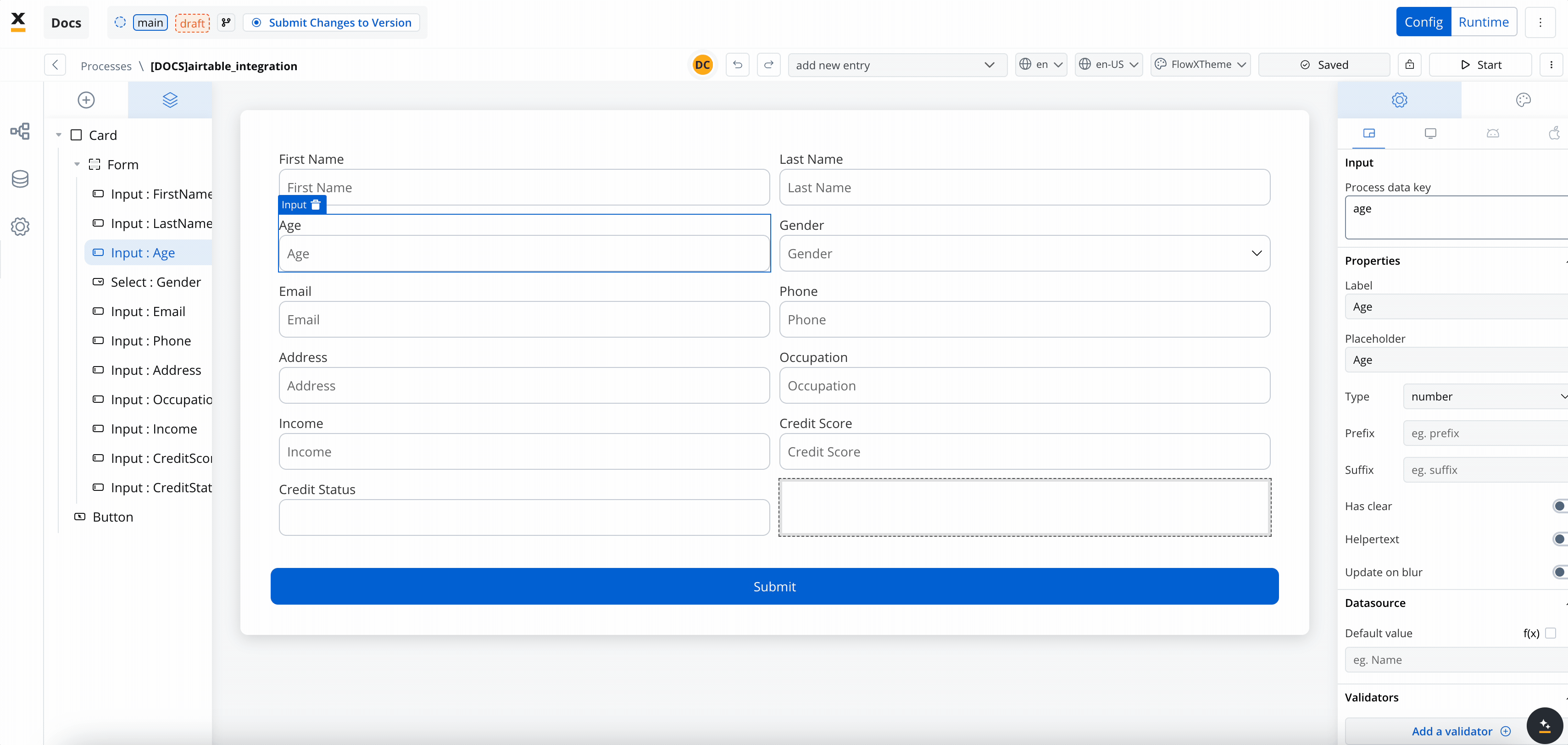
- Add a Start Integration Workflow node action:
- Make sure all the input will be captured.
Monitor Workflow and Capture Output
- Use the Receive Message Task to capture workflow outputs like status or returned data.
- Set up a Data stream topic to ensure workflow output is mapped to a predefined key.
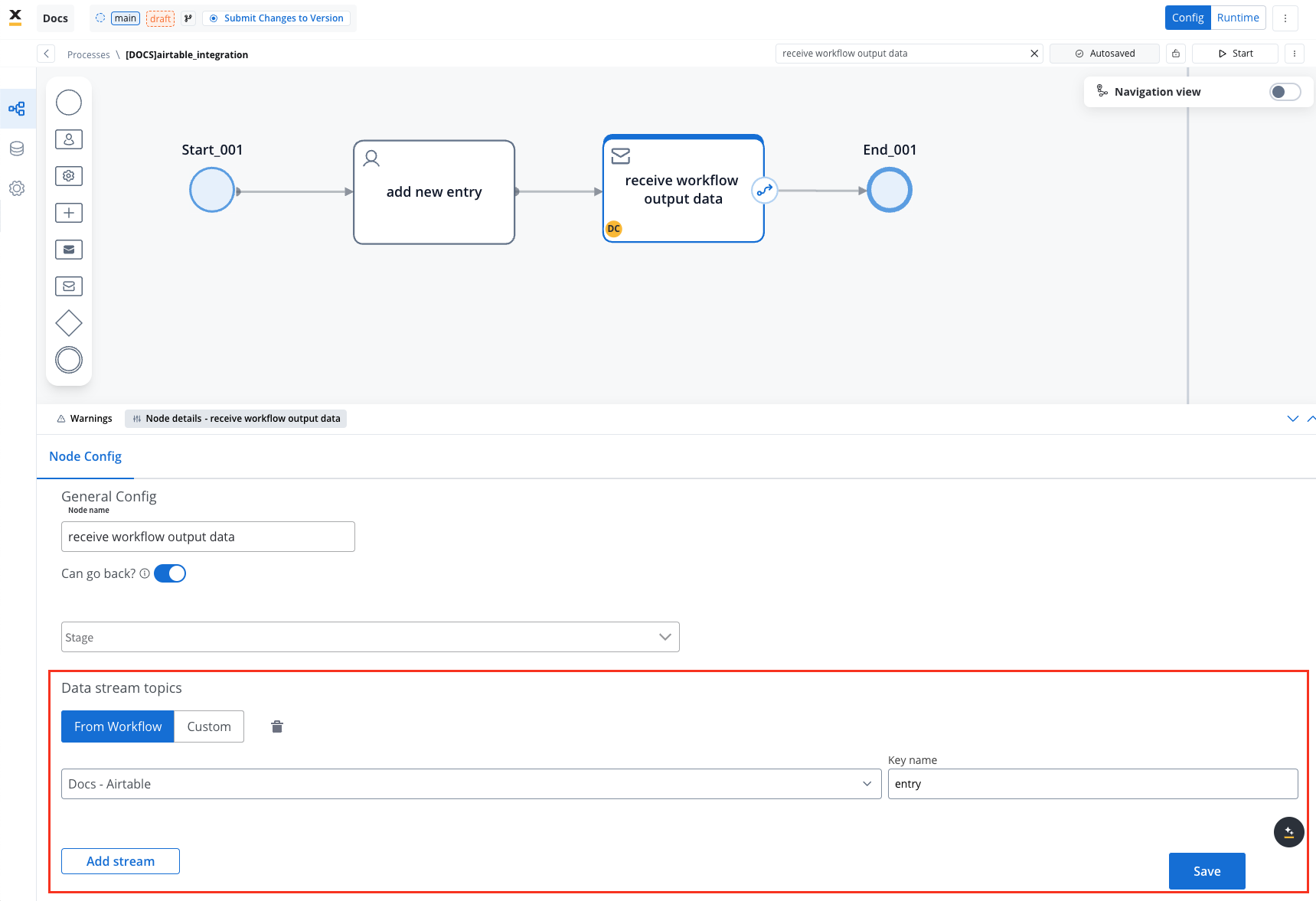
This example demonstrates how to integrate Airtable with FlowX to automate data management. You configured a data source, set up endpoints, designed a workflow, and linked it to a BPMN process.
Export and import
You can export and import both data sources and workflows as ZIP files to transfer them between projects or environments (for example, from development to UAT to production).Exporting
To export a data source or workflow:- Navigate to the Data Sources or Workflows list in Integration Designer
- Open the context menu for the resource you want to export
- Select Export
- The resource is downloaded as a ZIP file containing the full configuration
- Data Sources - data source configuration, endpoints, NoSQL operations, MCP tools
- Workflows - workflow nodes and their configurations
Importing
To import a data source or workflow:- Navigate to the Data Sources or Workflows list in Integration Designer
- Open the context menu and select Import from ZIP
- Select the ZIP file exported from another project or environment
- If resources with the same identifiers already exist, a Review Resource Identifiers Conflicts modal appears
- Choose a strategy for each conflicting resource (or use Apply to all):
- Keep both - imports the resource as a new copy alongside the existing one
- Replace - overwrites the existing resource with the imported version
- Skip this one - keeps the existing resource unchanged
- Click Continue to complete the import
FAQs
Can I call GraphQL, SOAP, or gRPC endpoints?
Can I call GraphQL, SOAP, or gRPC endpoints?
application/json and map the response as you would for any REST call.The Integration Designer also supports specialized data source types beyond REST: FlowX Database, Unmanaged MongoDB, MCP Server, Knowledge Base, Email Trigger, Email Sender, Incoming Webhook, and Microsoft Outlook. See Data sources for details.How is security handled in integrations??
How is security handled in integrations??
How are errors handled?
How are errors handled?
Can I import endpoint specifications in the Integration Designer?
Can I import endpoint specifications in the Integration Designer?
Can I cache responses from all endpoint methods?
Can I cache responses from all endpoint methods?
What happens if the cache service fails?
What happens if the cache service fails?
Can I use different cache policies for the same endpoint in different workflows?
Can I use different cache policies for the same endpoint in different workflows?
How do I know if my workflow is using cached data?
How do I know if my workflow is using cached data?